Here is the Dataframe I am working with:
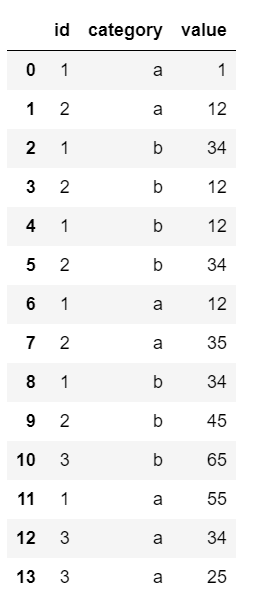
You can create it using the snippet:
my_dict = {'id': [1,2,1,2,1,2,1,2,1,2,3,1,3, 3],
'category':['a', 'a', 'b', 'b', 'b', 'b', 'a', 'a', 'b', 'b', 'b', 'a', 'a', 'a'],
'value' : [1, 12, 34, 12, 12 ,34, 12, 35, 34, 45, 65, 55, 34, 25]
}
x = pd.DataFrame(my_dict)
x
I want to filter IDs based on the condition: for category a, the count of values should be 2 and for category b, the count of values should be 3. Therefore, I would remove id 1 from category a and id 3 from category b from my original dataset x.
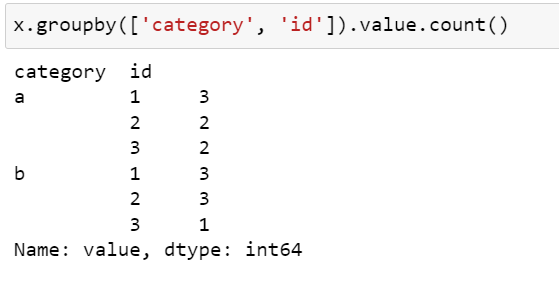
I can write the code for individual categories and start removing id's manually by using the code:
x.query('category == "a"').groupby('id').value.count().loc[lambda x: x != 2]
x.query('category == "b"').groupby('id').value.count().loc[lambda x: x != 3]
But, I don't want to do it manually since there are multiple categories. Is there a better way of doing it by considering all the categories at once and remove id's based on the condition listed in a list/dictionary?
CodePudding user response:
If need filter MultiIndex Series - s by dictionary use Index.get_level_values with Series.map and get equal values per groups in boolean indexing:
s = x.groupby(['category','id']).value.count()
d = {'a': 2, 'b': 3}
print (s[s.eq(s.index.get_level_values(0).map(d))])
category id
a 2 2
3 2
b 1 3
2 3
Name: value, dtype: int64
If need filter original DataFrame:
s = x.groupby(['category','id'])['value'].transform('count')
print (s)
0 3
1 2
2 3
3 3
4 3
5 3
6 3
7 2
8 3
9 3
10 1
11 3
12 2
13 2
Name: value, dtype: int64
d = {'a': 2, 'b': 3}
print (x[s.eq(x['category'].map(d))])
id category value
1 2 a 12
2 1 b 34
3 2 b 12
4 1 b 12
5 2 b 34
7 2 a 35
8 1 b 34
9 2 b 45
12 3 a 34
13 3 a 25