I have a data frame df of around 10 million employees. Each employee has an ID and there is a city variable and a company variable that shows where they work:
ID city company
1 NYC ABC
2 BOS ABC
1 NYC DEF
3 SEA GHI
I want to group_by ID and city and then figure out the number of companies each employee works for:
ID city count
1 NYC 2
2 BOS 1
3 SEA 1
My code is df %>% group_by(ID, city) %>% summarize(count = n_distinct(company))
However, this is taking a long time to run. My set-up typically supports computationally heavy operations, but I am having a hard time running this chunk of code.
Does anyone have a different (ideally faster implementation)?
Edit: n_distinct(company) instead of n_distinct(ID)
CodePudding user response:
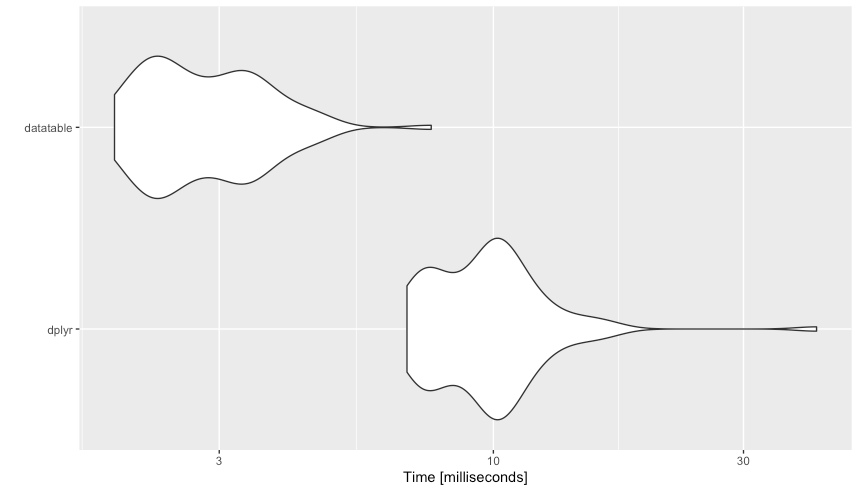
Here is a benchmark comparison of a data.table and dplyr solution using a larger (and hopefully representative?) dataset.
# Sample data
df <- data.frame(
ID = sample(c(1:10), 10000, replace = TRUE),
city = sample(c("NYC", "BOS", "SEA"), 10000, replace = TRUE),
company = sample(c("ABC", "DEF", "GHI","JKL", "MNO", "PQR", "STU"), 10000, replace = TRUE))
library(data.table)
dt <- as.data.table(df)
library(microbenchmark)
res <- microbenchmark(
dplyr = df %>%
group_by(ID, city) %>%
summarise(count = n_distinct(company), .groups = "drop"),
datatable = dt[, .(count = uniqueN(company)), by = c("ID", "city")]
)
res
#Unit: milliseconds
# expr min lq mean median uq max neval
# dplyr 6.843204 7.696959 10.110256 9.915225 10.906205 41.35438 100
#datatable 1.893994 2.255023 2.924953 2.738450 3.395504 7.61165 100
autoplot(res)
CodePudding user response:
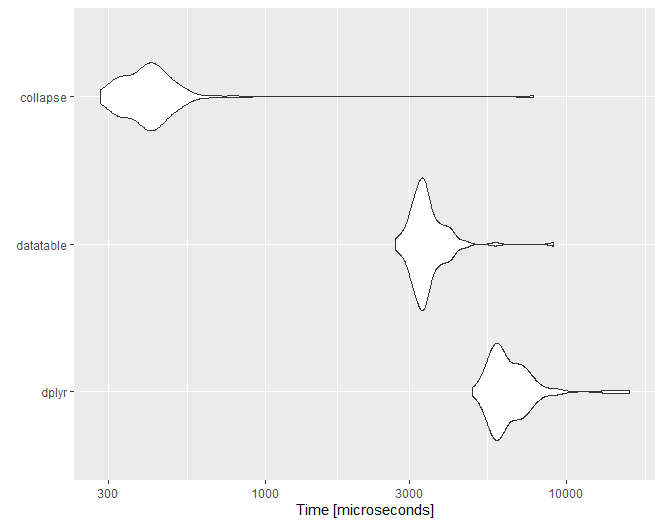
We have another option. We can use the collapse package, which is C/C based package for data manipulation. The syntax is similar to dplyr. In the following example, fgroup_by, fsummarise, and fndistinct are from the collapse package, which perform the same task as group_by, summarise, and n_distinct from dplyr.
library(dplyr)
library(collapse)
dat <- read.table(textConnection("ID city company
1 NYC ABC
2 BOS ABC
1 NYC DEF
3 SEA GHI"), header = TRUE)
dat %>%
fgroup_by(ID, city) %>%
fsummarise(count = fndistinct(company))
# ID city count
# 1 1 NYC 2
# 2 2 BOS 1
# 3 3 SEA 1
Below is a speed comparison. I modified the examples and code from @Maurits Evers.
library(dplyr)
library(data.table)
library(collapse)
library(ggplot2)
library(microbenchmark)
# Sample data
df <- data.frame(
ID = sample(c(1:10), 10000, replace = TRUE),
city = sample(c("NYC", "BOS", "SEA"), 10000, replace = TRUE),
company = sample(c("ABC", "DEF", "GHI","JKL", "MNO", "PQR", "STU"), 10000, replace = TRUE))
dt <- as.data.table(df)
res <- microbenchmark(
dplyr = df %>%
group_by(ID, city) %>%
summarise(count = n_distinct(company), .groups = "drop"),
datatable = dt[, .(count = uniqueN(company)), by = c("ID", "city")],
collapse = df %>%
fgroup_by(ID, city) %>%
fsummarise(count = fndistinct(company))
)
res
# Unit: microseconds
# expr min lq mean median uq max neval cld
# dplyr 4885.501 5776.400 6658.784 6108.901 7073.8015 16177.301 100 c
# datatable 2705.501 3173.351 3500.120 3332.501 3643.5510 9076.502 100 b
# collapse 283.001 347.251 482.880 402.901 452.2505 7740.401 100 a