Working on one of my first Python projects independently so hopefully this is instructive as it is useful in figuring out my data and research question!
- The problem: I am looking to do some EDA on a Pandas dataframe of 51,299 recruits from a football recruiting database. I've imported the data, cleaned it to get the right structure for each variable, but now that I am exploring some bar plots, I've run into an issue of incorrect x-axis. Note that the picture below won't replicate exactly with dummy data provided.
- What I have tried: My bar plots comparing any variable by year all list the same year across the x-axis (2006 - first year of dataset) and are just all equal length vertical bars. All relevant code, data and plot image are shown below:
Data:
import numpy as np
import string
np.random.seed(1234)
name = [list(np.random.choice(list(string.ascii_lowercase), 5))] #to keep relatively anonymous
#print(name)
import pandas as pd
import matplotlib.pyplot as plt
#example data with same colnames:
cols = ['ident', 'rank', 'name', 'year', 'rating', 'stars', 'position', 'commit']
ident = [8263, 8264, 8265, 8266, 8267]
rank = [1, 2, 3, 4, 5]
name = ['n', 'c', 'd', 'g', 'r']
year = [2006, 2006, 2006, 2007, 2007] #but, in my full dataset it's thousands of 2006's...
rating = [0.9993, 0.9989, 0.9984, 0.9980, 0.9977]
stars = [5, 5, 5, 5, 5]
position = ['OG', 'WR', 'WR', 'ILB', 'S']
commit = ['School A', 'School B', 'School C', 'School D', 'School E']
recruit_df = pd.DataFrame(list(zip(ident, rank, name, year, rating, stars, position, commit)),
index = ident, columns = cols)
#recruit_df.head()
Plotting code and incorrect output:
fig, ax = plt.subplots()
ax.bar(recruit_df["year"], recruit_df["rating"].mean())
ax.set_xticklabels(recruit_df["year"], rotation=90)
ax.set_ylabel("Ratings of recruits by year")
plt.show()
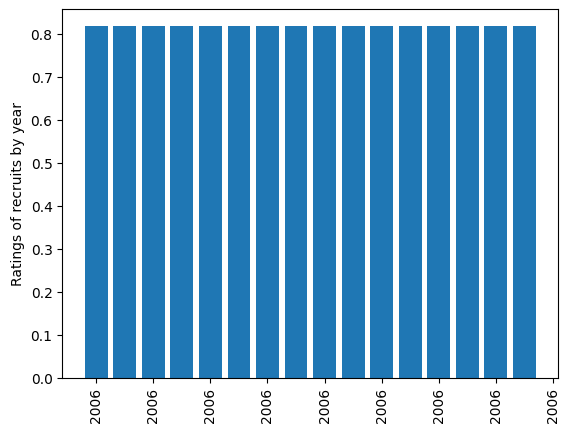
Thoughts on what I am doing wrong? Thank you as always!
CodePudding user response:
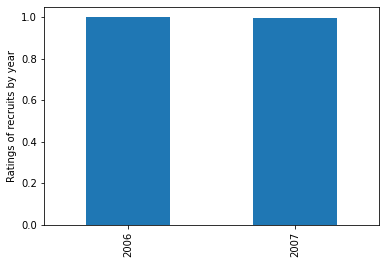
Use groupby mean, and let pandas do (most of) the plotting work for you.
recruit_df.groupby('year')['rating'].mean().plot.bar(ax=ax, legend=False)
ax.set_ylabel('Ratings of recruits by year')
ax.set_xlabel('')
Output with your sample data:
CodePudding user response:
To expand a bit on @BigBen's answer, think about what this line is doing:
ax.bar(recruit_df["year"], recruit_df["rating"].mean())
According to the Matplotlib bar plot documentation, axes.bar plots bars at the given x-coordinates with the given heights.
The x-coordinate values that you've passed in is from recruit_df["year"], which is just a list of the years, so Matplotlib is going to create a bar at each one of those spots (2006, another 2006, another 2006, etc...) - it doesn't know that you only want one 2006 bar.
For the heights of the bars, you're passing in recruit_df["rating"].mean(). If you try printing that out, you'll find that it's just a single value that's the average of all of the individual ratings across all years.
So with all of that together, you're telling Matplotlib to put a bar at each of the date values in the year column (51,299 bars in total) and to make each bar the height of the average for all of the rating values.
Matplotlib on its own can't group data and do stats on it, which is why @BigBen suggested using the groupby function in Pandas.
recruit_df.groupby("year").mean() will group the dataframe by year (the years become the index of the newly created dataframe) and provide an average value for each (numeric) column.
Adding ["rating"] either before or after .mean() will select only the rating column, then adding .plot.bar will tell Pandas to plot the average rating against the index (the years).
If you want to create the plot in a similar way to what you did before, it's probably easiest to turn the grouped dataframe into its own dataframe or series object. For a dataframe, that would be something like this:
recruit_mean = recruit_df.groupby("year").mean()
ax.bar(recruit_mean.index, recruit_mean["rating"])
ax.set_xticks(recruit_mean.index, labels = recruit_mean.index, rotation = 90)
The first line creates a new dataframe (see below if you want to do a series instead) that has the years as the index and the mean values of all numeric columns for those years as the columns.
The second line creates the bar plot. recruit_mean.index is the list of years that serve as your x-coordinates. recruit_mean["rating"] is the rating column that has the mean at each index (year) value.
I used ax.set_xticks instead of ax.set_xticklabels since it provides a bit more flexibility for creating the ticks (the first argument is the position of the ticks) and labels.
To create a grouped series instead of dataframe, you can do the following:
recruit_mean_series = recruit_df.groupby("year")["rating"].mean()
ax.bar(recruit_mean_series.index, recruit_mean_series)
ax.set_xticks(recruit_mean_series.index, labels = recruit_mean_series.index, rotation = 90)
Notice how with the series, you don't call recruit_mean_series["rating"]. Because a series is essentially just a single column, the column itself doesn't have a name by default, so trying to call a column name will result in an error. Instead, calling the series with recruit_mean_series returns the values in the series.