I was able to solve the problem described below, but as I am a newbie, I am not sure if my solution is good. I'd be grateful for any tips on how to do it in a more efficient and/or more elegant manner.
What I have:
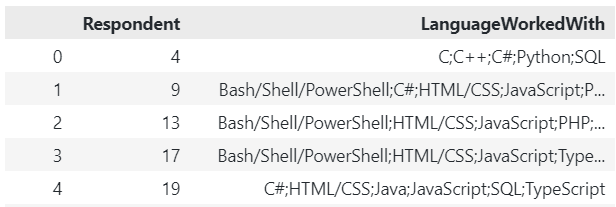
...and so on (the table's quite big).
What I need:
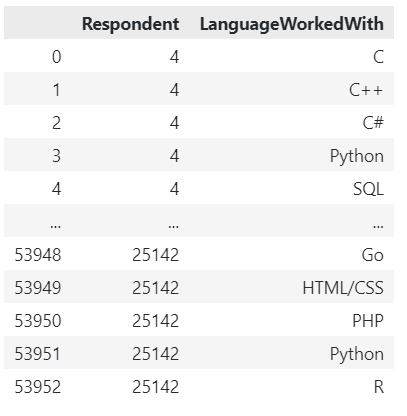
How I solved it:
Load the file
df = pd.read_csv("survey_data_cleaned_ver2.csv")
Define a function
def transform_df(df, list_2, column_2, list_1, column_1='Respondent'):
for ind in df.index:
elements = df[column_2][ind].split(';')
num_of_elements = len(elements)
for num in range(num_of_elements):
list_1.append(df['Respondent'][ind])
for el in elements:
list_2.append(el)
Dropna because NaNs are floats and that was causing errors later on.
df_LanguageWorkedWith = df[['Respondent', 'LanguageWorkedWith']]
df_LanguageWorkedWith.dropna(subset='LanguageWorkedWith', inplace=True)
Create empty lists
Respondent_As_List = []
LanguageWorkedWith_As_List = []
Call the function
transform_df(df_LanguageWorkedWith, LanguageWorkedWith_As_List, 'LanguageWorkedWith', Respondent_As_List)
Tranform the lists into dataframes
df_Respondent = pd.DataFrame(Respondent_As_List, columns=["Respondent"])
df_LanguageWorked = pd.DataFrame(LanguageWorkedWith_As_List, columns=["LanguageWorkedWith"])
Concatenate those dataframes
df_LanguageWorkedWith_final = pd.concat([df_Respondent, df_LanguageWorked], axis=1)
And that's it.
The code and input file can be found on my GitHub: https://github.com/jarsonX/Temp_files
Thanks in advance!
CodePudding user response:
You can try like this. I haven't tested but it should work
df['LanguageWorkedWith'] = df['LanguageWorkedWith'].str.replace(';',',')
df =df.assign(LanguageWorkedWith=df['LanguageWorkedWith'].str.split(',')).explode('LanguageWorkedWith')
#Tested
LanguageWorkedWith Respondent
0 C 4
0 C 4
0 C# 4
0 Python 4
0 SQL 4
... ... ...
10319 Go 25142