Dataset is something like this (there will be duplicate rows in the original):
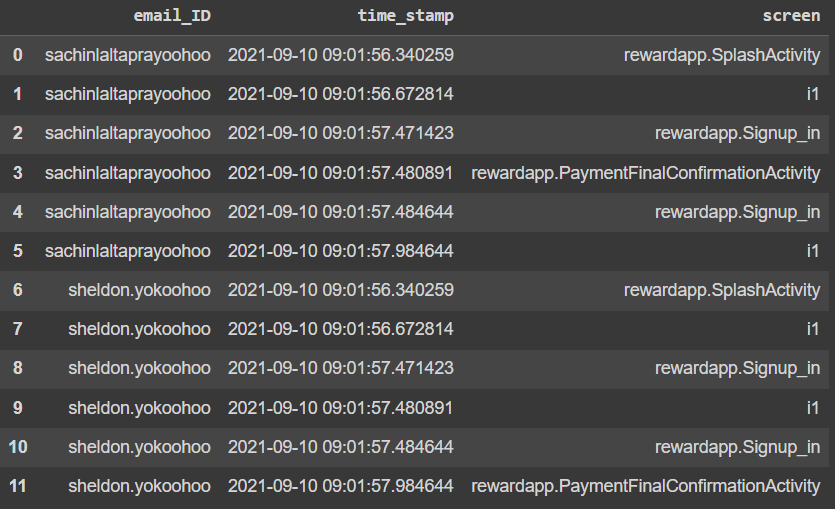
Code:
import pandas as pd
df_in = pd.DataFrame({'email_ID': {0: 'sachinlaltaprayoohoo',
1: 'sachinlaltaprayoohoo',
2: 'sachinlaltaprayoohoo',
3: 'sachinlaltaprayoohoo',
4: 'sachinlaltaprayoohoo',
5: 'sachinlaltaprayoohoo',
6: 'sheldon.yokoohoo',
7: 'sheldon.yokoohoo',
8: 'sheldon.yokoohoo',
9: 'sheldon.yokoohoo',
10: 'sheldon.yokoohoo',
11: 'sheldon.yokoohoo'},
'time_stamp': {0: '2021-09-10 09:01:56.340259',
1: '2021-09-10 09:01:56.672814',
2: '2021-09-10 09:01:57.471423',
3: '2021-09-10 09:01:57.480891',
4: '2021-09-10 09:01:57.484644',
5: '2021-09-10 09:01:57.984644',
6: '2021-09-10 09:01:56.340259',
7: '2021-09-10 09:01:56.672814',
8: '2021-09-10 09:01:57.471423',
9: '2021-09-10 09:01:57.480891',
10: '2021-09-10 09:01:57.484644',
11: '2021-09-10 09:01:57.984644'},
'screen': {0: 'rewardapp.SplashActivity',
1: 'i1',
2: 'rewardapp.Signup_in',
3: 'rewardapp.PaymentFinalConfirmationActivity',
4: 'rewardapp.Signup_in',
5: 'i1',
6: 'rewardapp.SplashActivity',
7: 'i1',
8: 'rewardapp.Signup_in',
9: 'i1',
10: 'rewardapp.Signup_in',
11: 'rewardapp.PaymentFinalConfirmationActivity'}})
df_in['time_stamp'] = df_in['time_stamp'].astype('datetime64[ns]')
df_in
Output should be this:
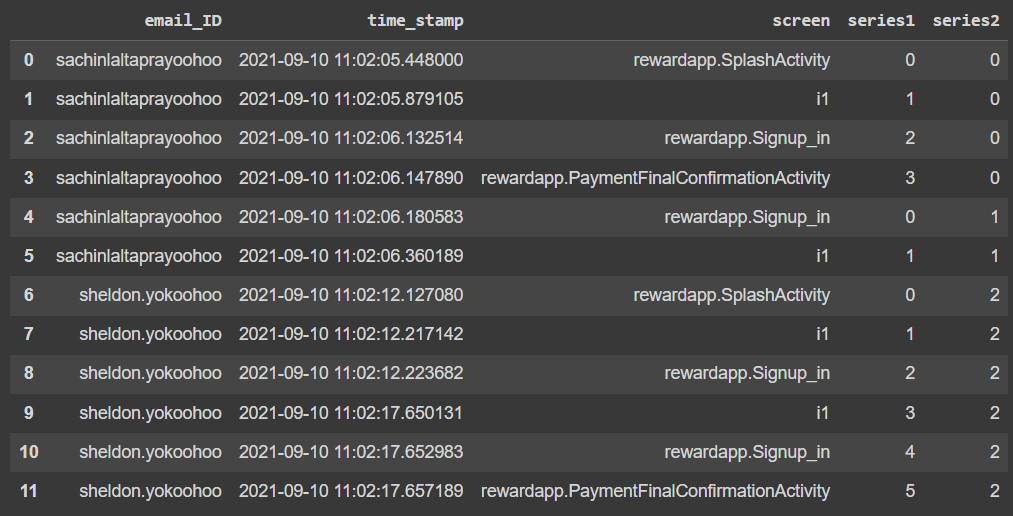
Code:
import pandas as pd
df_out = pd.DataFrame({'email_ID': {0: 'sachinlaltaprayoohoo',
1: 'sachinlaltaprayoohoo',
2: 'sachinlaltaprayoohoo',
3: 'sachinlaltaprayoohoo',
4: 'sachinlaltaprayoohoo',
5: 'sachinlaltaprayoohoo',
6: 'sheldon.yokoohoo',
7: 'sheldon.yokoohoo',
8: 'sheldon.yokoohoo',
9: 'sheldon.yokoohoo',
10: 'sheldon.yokoohoo',
11: 'sheldon.yokoohoo'},
'time_stamp': {0: '2021-09-10 09:01:56.340259',
1: '2021-09-10 09:01:56.672814',
2: '2021-09-10 09:01:57.471423',
3: '2021-09-10 09:01:57.480891',
4: '2021-09-10 09:01:57.484644',
5: '2021-09-10 09:01:57.984644',
6: '2021-09-10 09:01:56.340259',
7: '2021-09-10 09:01:56.672814',
8: '2021-09-10 09:01:57.471423',
9: '2021-09-10 09:01:57.480891',
10: '2021-09-10 09:01:57.484644',
11: '2021-09-10 09:01:57.984644'},
'screen': {0: 'rewardapp.SplashActivity',
1: 'i1',
2: 'rewardapp.Signup_in',
3: 'rewardapp.PaymentFinalConfirmationActivity',
4: 'rewardapp.Signup_in',
5: 'i1',
6: 'rewardapp.SplashActivity',
7: 'i1',
8: 'rewardapp.Signup_in',
9: 'i1',
10: 'rewardapp.Signup_in',
11: 'rewardapp.PaymentFinalConfirmationActivity'},
'series1': {0: 0,
1: 1,
2: 2,
3: 3,
4: 0,
5: 1,
6: 0,
7: 1,
8: 2,
9: 3,
10: 4,
11: 5},
'series2': {0: 0,
1: 0,
2: 0,
3: 0,
4: 1,
5: 1,
6: 2,
7: 2,
8: 2,
9: 2,
10: 2,
11: 2}})
df_out['time_stamp'] = df['time_stamp'].astype('datetime64[ns]')
df_out
'series1' column values starts row by row as 0, 1, 2, and so on but resets to 0 when:
- 'email_ID' column value changes.
- 'screen' column value == 'rewardapp.PaymentFinalConfirmationActivity'
'series2' column values starts with 0 and increments by 1 whenever 'series1' resets.
My progress:
series1 = [0]
x = 0
for index in df[1:].index:
if ((df._get_value(index - 1, 'email_ID')) == df._get_value(index, 'email_ID')) and (df._get_value(index - 1, 'screen') != 'rewardapp.PaymentFinalConfirmationActivity'):
x = 1
series1.append(x)
else:
x = 0
series1.append(x)
df['series1'] = series1
df
series2 = [0]
x = 0
for index in df[1:].index:
if df._get_value(index, 'series1') - df._get_value(index - 1, 'series1') == 1:
series2.append(x)
else:
x = 1
series2.append(x)
df['series2'] = series2
df
I think the code above is working, I'll test answered codes and select the best in a few hours, thank you.
CodePudding user response:
Let's try
m = (df_in['email_ID'].ne(df_in['email_ID'].shift().bfill()) |
df_in['screen'].shift().eq('rewardapp.PaymentFinalConfirmationActivity'))
df_in['series1'] = df_in.groupby(m.cumsum()).cumcount()
df_in['series2'] = m.cumsum()
print(df_in)
email_ID time_stamp screen series1 series2
0 sachinlaltaprayoohoo 2021-09-10 09:01:56.340259 rewardapp.SplashActivity 0 0
1 sachinlaltaprayoohoo 2021-09-10 09:01:56.672814 i1 1 0
2 sachinlaltaprayoohoo 2021-09-10 09:01:57.471423 rewardapp.Signup_in 2 0
3 sachinlaltaprayoohoo 2021-09-10 09:01:57.480891 rewardapp.PaymentFinalConfirmationActivity 3 0
4 sachinlaltaprayoohoo 2021-09-10 09:01:57.484644 rewardapp.Signup_in 0 1
5 sachinlaltaprayoohoo 2021-09-10 09:01:57.984644 i1 1 1
6 sheldon.yokoohoo 2021-09-10 09:01:56.340259 rewardapp.SplashActivity 0 2
7 sheldon.yokoohoo 2021-09-10 09:01:56.672814 i1 1 2
8 sheldon.yokoohoo 2021-09-10 09:01:57.471423 rewardapp.Signup_in 2 2
9 sheldon.yokoohoo 2021-09-10 09:01:57.480891 i1 3 2
10 sheldon.yokoohoo 2021-09-10 09:01:57.484644 rewardapp.Signup_in 4 2
11 sheldon.yokoohoo 2021-09-10 09:01:57.984644 rewardapp.PaymentFinalConfirmationActivity 5 2
CodePudding user response:
You can use:
m = df_in['screen']=='rewardapp.PaymentFinalConfirmationActivity'
df_in['pf'] = np.where(m, 1, np.nan)
df_in.loc[m, 'pf'] = df_in[m].cumsum()
grouper = df_in.groupby('email_ID')['pf'].bfill()
df_in['series1'] = df_in.groupby(grouper).cumcount()
df_in['series2'] = df_in.groupby(grouper.fillna(0), sort=False).ngroup()
df_in.drop('pf', axis=1, inplace=True)
print(df_in):
email_ID time_stamp \
0 sachinlaltaprayoohoo 2021-09-10 09:01:56.340259
1 sachinlaltaprayoohoo 2021-09-10 09:01:56.672814
2 sachinlaltaprayoohoo 2021-09-10 09:01:57.471423
3 sachinlaltaprayoohoo 2021-09-10 09:01:57.480891
4 sachinlaltaprayoohoo 2021-09-10 09:01:57.484644
5 sachinlaltaprayoohoo 2021-09-10 09:01:57.984644
6 sheldon.yokoohoo 2021-09-10 09:01:56.340259
7 sheldon.yokoohoo 2021-09-10 09:01:56.672814
8 sheldon.yokoohoo 2021-09-10 09:01:57.471423
9 sheldon.yokoohoo 2021-09-10 09:01:57.480891
10 sheldon.yokoohoo 2021-09-10 09:01:57.484644
11 sheldon.yokoohoo 2021-09-10 09:01:57.984644
screen series1 series2
0 rewardapp.SplashActivity 0 0
1 i1 1 0
2 rewardapp.Signup_in 2 0
3 rewardapp.PaymentFinalConfirmationActivity 3 0
4 rewardapp.Signup_in 0 1
5 i1 1 1
6 rewardapp.SplashActivity 0 2
7 i1 1 2
8 rewardapp.Signup_in 2 2
9 i1 3 2
10 rewardapp.Signup_in 4 2
11 rewardapp.PaymentFinalConfirmationActivity 5 2
Explanation:
- First locate the rows where 'screen' is 'PaymentFinalConfirmationActivity' and then use
cumsum()to identify their numbers. This is accomplished by:
df_in['pf'] = np.where(m, 1, np.nan)
df_in.loc[m, 'pf'] = df_in[m].cumsum()
- Then use
bfillto backfill the NaN values with the positions where 'screen' shows 'PaymentFinalConfirmationActivity'. This will ensure the above rows are of the same group, but do it per email_ID. This is accomplished by:
grouper = df_in.groupby('email_ID')['pf'].bfill()
- Then it is straightforward to see that once you define a grouper, you can use
cumcountto get theseries1column. This is done by:
df_in['series1'] = df_in.groupby(grouper).cumcount()
- Then get
series2column by usingngroup(). But make sure the groupby is done withsort=False. Done by:
df_in['series2'] = df_in.groupby(grouper.fillna(0), sort=False).ngroup()
- Finally drop the unwanted column
pf.
df_in.drop('pf', axis=1, inplace=True)