I want to have a function that creates a new dataframe from two dataframes.
I want to show the mismatched columns based on id number and a given column.
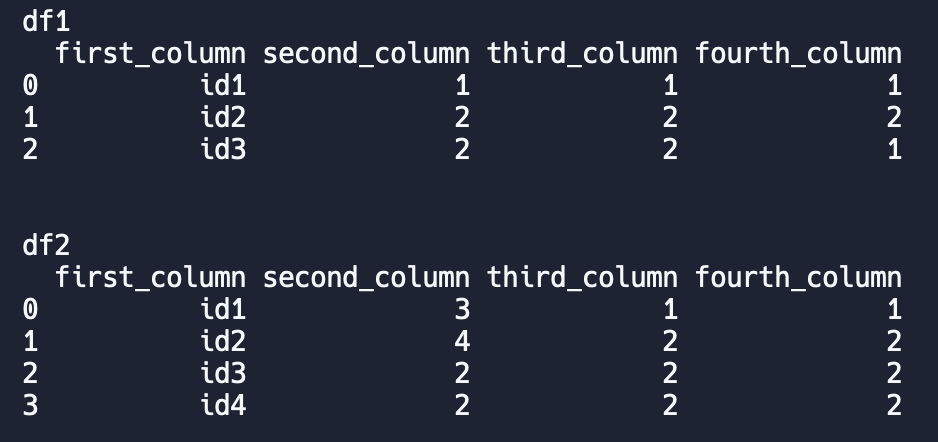 dataframes as input:
dataframes as input:
import pandas as pd
data1 = {
'first_column': ['id1', 'id2', 'id3'],
'second_column': ['1', '2', '2'],
'third_column': ['1', '2', '2'],
'fourth_column': ['1', '2', '1']
}
df1 = pd.DataFrame(data1)
print("\n")
print("df1")
print(df1)
data2 = {
'first_column': ['id1', 'id2', 'id3', 'id4'],
'second_column': ['3', '4', '2', '2'],
'third_column': ['1', '2', '2', '2'],
'fourth_column': ['1', '2', '2', '2']
}
df2 = pd.DataFrame(data2)
expected output:

CodePudding user response:
Is that something you were looking for:
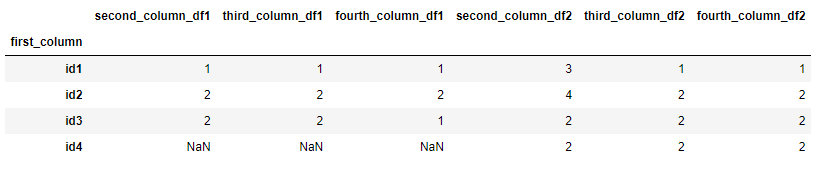
df1 = df1.set_index('first_column')
df2 = df2.set_index('first_column')
df1.columns = df1.columns '_df1'
df2.columns = df2.columns '_df2'
df_out = pd.concat([df1, df2], axis = 1)
Which gives you:
If you're bothered about first_column in the index:
df_out = df_out.reset_index(inplace = False)
Which gives you:

CodePudding user response:
STEP 1 // add the table name Prefix on column name
df1.columns = df1.columns '_df1'
df2.columns = df2.columns '_df2'
STEP 2 // Concat both df
data = pd.concat([df1.set_index('first_column_df1'),df2.set_index('first_column_df2')],axis=1, join='outer').reset_index(drop=False)
STEP 3 // Using lambda function findout which row second column does math if does match return True and print only DF rows where condition came True
data = data[data.apply(lambda x: x.second_column_df1 != x.second_column_df2 ,axis=1)]
STEP 4 // To achieve desire output
data = data[data['second_column_df2'].notna()]
data[['index', 'second_column_df1', 'second_column_df2']].reset_index(drop=True)
Output:
index second_column_df1 second_column_df2
0 id1 1 3
1 id2 2 4
2 id4 NaN 2