I have CSV dataset like this:
"len","supp","dose"
4.2,"VC",0.5
11.5,"VC",0.5
7.3,"VC",0.5
5.8,"VC",0.5
6.4,"VC",0.5
10,"VC",0.5
11.2,"VC",0.5
11.2,"VC",0.5
5.2,"VC",0.5
7,"VC",0.5
16.5,"VC",1
16.5,"VC",1
15.2,"VC",1
17.3,"VC",1
22.5,"VC",1
17.3,"VC",1
13.6,"VC",1
14.5,"VC",1
18.8,"VC",1
15.5,"VC",1
23.6,"VC",2
18.5,"VC",2
33.9,"VC",2
25.5,"VC",2
26.4,"VC",2
32.5,"VC",2
26.7,"VC",2
21.5,"VC",2
23.3,"VC",2
29.5,"VC",2
15.2,"OJ",0.5
21.5,"OJ",0.5
17.6,"OJ",0.5
9.7,"OJ",0.5
14.5,"OJ",0.5
10,"OJ",0.5
8.2,"OJ",0.5
9.4,"OJ",0.5
16.5,"OJ",0.5
9.7,"OJ",0.5
19.7,"OJ",1
23.3,"OJ",1
23.6,"OJ",1
26.4,"OJ",1
20,"OJ",1
25.2,"OJ",1
25.8,"OJ",1
21.2,"OJ",1
14.5,"OJ",1
27.3,"OJ",1
25.5,"OJ",2
26.4,"OJ",2
22.4,"OJ",2
24.5,"OJ",2
24.8,"OJ",2
30.9,"OJ",2
26.4,"OJ",2
27.3,"OJ",2
29.4,"OJ",2
23,"OJ",2
I need to calculate mean and standart deviation by grouping "supp" and "dose" using Python Pandas modules. Result should look like this:
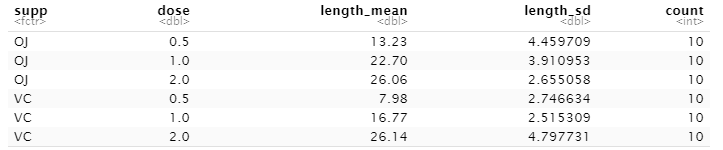
I tried using agg function but it seems that isn't really working
data = data.groupby(['supp', 'dose']).agg({['mean', 'std']})
Is it possible to calculate mean and std at once in Python Pandas modules?
CodePudding user response:
You can also rename the new column name in agg similar to in R:
df.groupby(['supp', 'dose'], as_index=False).agg(length_mean=('len', 'mean'),\
length_std=('len', 'std'),\
count=('len', 'count'))
Output:
supp dose length_mean length_std count
0 OJ 0.5 13.23 4.459709 10
1 OJ 1.0 22.70 3.910953 10
2 OJ 2.0 26.06 2.655058 10
3 VC 0.5 7.98 2.746634 10
4 VC 1.0 16.77 2.515309 10
5 VC 2.0 26.14 4.797731 10