I created 8 exams using the r exams package (each with the corresponding *.rds file). Each exam has the same 8 items (in a different order). All exams' *.rds were merged into a single list. As follows:
exams_list <- list(`00001` = list(exercise1 = list(question = c("\\emph{(2 \\myPoints)}",
"Q1"), questionlist = c("A1", "A2","A3", "A4", "A5"), solution = NULL,
solutionlist = NULL, metainfo = list(file = "stat1_en_descriptive_stat_34",
markup = "latex", type = "schoice", name = "stat1_en_descriptive_stat_34",
title = NULL, section = NULL, version = NULL, solution = c(FALSE,
FALSE, FALSE, TRUE, FALSE), clozetype = NULL, points = 2,
time = NULL, shuffle = 5, length = 5L, string = "stat1_en_descriptive_stat_34: b",
maxchars = NULL, abstention = NULL, stringtype = NULL,
seed = 40283L), supplements = structure(character(0), names = character(0), dir = "/tmp/RtmpH83QPG/file808555d833f/exam1/exercise1")),
exercise2 = list(question = c("\\emph{(2 \\myPoints)}", "Q2",
"", "\\hfill\\break", "\\includegraphics[width=0.55\\textwidth,height=\\textheight]{stat1_descriptive_stat_10.png}"
), questionlist = c("A1", "A2","A3", "A4", "A5"
), solution = NULL, solutionlist = NULL, metainfo = list(
file = "stat1_en_descriptive_stat_10", markup = "latex",
type = "schoice", name = "stat1_en_descriptive_stat_10",
title = NULL, section = NULL, version = NULL, solution = c(FALSE,
TRUE, FALSE, FALSE, FALSE), clozetype = NULL, points = 2,
time = NULL, shuffle = 5, length = 5L, string = "stat1_en_descriptive_stat_10: b",
maxchars = NULL, abstention = NULL, stringtype = NULL,
seed = 23616L), supplements = structure(c(stat1_descriptive_stat_10.png = "/tmp/RtmpH83QPG/file808555d833f/exam1/exercise2/stat1_descriptive_stat_10.png"), dir = "/tmp/RtmpH83QPG/file808555d833f/exam1/exercise2")),
exercise3 = list(question = c("\\emph{(2 \\myPoints)}", "Q3"
), questionlist = c("A1", "A2","A3", "A4", "A5"),
solution = NULL, solutionlist = NULL, metainfo = list(
file = "stat1_en_descriptive_stat_15", markup = "latex",
type = "schoice", name = "stat1_en_descriptive_stat_15",
title = NULL, section = NULL, version = NULL, solution = c(FALSE,
FALSE, FALSE, TRUE, FALSE), clozetype = NULL, points = 2,
time = NULL, shuffle = 5, length = 5L, string = "stat1_en_descriptive_stat_15: d",
maxchars = NULL, abstention = NULL, stringtype = NULL,
seed = 84038L), supplements = structure(character(0), names = character(0), dir = "/tmp/RtmpH83QPG/file808555d833f/exam1/exercise3")),
exercise4 = list(question = c("\\emph{(2 \\myPoints)}", "Q4"), questionlist = c("A1", "A2","A3", "A4", "A5"), solution = NULL, solutionlist = NULL,
metainfo = list(file = "stat1_en_descriptive_stat_29",
markup = "latex", type = "schoice", name = "stat1_en_descriptive_stat_29",
title = NULL, section = NULL, version = NULL, solution = c(FALSE,
FALSE, FALSE, TRUE, FALSE), clozetype = NULL, points = 2,
time = NULL, shuffle = 5, length = 5L, string = "stat1_en_descriptive_stat_29: d",
maxchars = NULL, abstention = NULL, stringtype = NULL,
seed = 104204L), supplements = structure(character(0), names = character(0), dir = "/tmp/RtmpH83QPG/file808555d833f/exam1/exercise4")),
exercise5 = list(question = c("\\emph{(2 \\myPoints)}", "Q5"
), questionlist = c("A1", "A2","A3", "A4", "A5"), solution = NULL,
solutionlist = NULL, metainfo = list(file = "stat1_en_prob_8",
markup = "latex", type = "schoice", name = "stat1_en_prob_8",
title = NULL, section = NULL, version = NULL, solution = c(FALSE,
FALSE, TRUE, FALSE, FALSE), clozetype = NULL, points = 2,
time = NULL, shuffle = 5, length = 5L, string = "stat1_en_prob_8: c",
maxchars = NULL, abstention = NULL, stringtype = NULL,
seed = 99878L), supplements = structure(character(0), names = character(0), dir = "/tmp/RtmpH83QPG/file808555d833f/exam1/exercise5"))),
`00002` = list(exercise1 = list(question = c("\\emph{(2 \\myPoints)}",
"Q1"), questionlist = c("A1", "A2","A3", "A4", "A5"
), solution = NULL, solutionlist = NULL, metainfo = list(
file = "stat1_en_descriptive_stat_10", markup = "latex",
type = "schoice", name = "stat1_en_descriptive_stat_10",
title = NULL, section = NULL, version = NULL, solution = c(FALSE,
FALSE, TRUE, FALSE, FALSE), clozetype = NULL, points = 2,
time = NULL, shuffle = 5, length = 5L, string = "stat1_en_descriptive_stat_10: c",
maxchars = NULL, abstention = NULL, stringtype = NULL,
seed = 66957L), supplements = structure(c(stat1_descriptive_stat_10.png = "/tmp/RtmpH83QPG/file8087677e29b/exam1/exercise1/stat1_descriptive_stat_10.png"), dir = "/tmp/RtmpH83QPG/file8087677e29b/exam1/exercise1")),
exercise2 = list(question = c("\\emph{(2 \\myPoints)}",
"Q2"),
questionlist = c("A1", "A2","A3", "A4", "A5"), solution = NULL,
solutionlist = NULL, metainfo = list(file = "stat1_en_descriptive_stat_34",
markup = "latex", type = "schoice", name = "stat1_en_descriptive_stat_34",
title = NULL, section = NULL, version = NULL,
solution = c(FALSE, FALSE, FALSE, TRUE, FALSE
), clozetype = NULL, points = 2, time = NULL,
shuffle = 5, length = 5L, string = "stat1_en_descriptive_stat_34: a",
maxchars = NULL, abstention = NULL, stringtype = NULL,
seed = 24446L), supplements = structure(character(0), names = character(0), dir = "/tmp/RtmpH83QPG/file8087677e29b/exam1/exercise2")),
exercise3 = list(question = c("\\emph{(2 \\myPoints)}",
"Q3"), questionlist = c("A1", "A2","A3", "A4", "A5"), solution = NULL, solutionlist = NULL,
metainfo = list(file = "stat1_en_descriptive_stat_29",
markup = "latex", type = "schoice", name = "stat1_en_descriptive_stat_29",
title = NULL, section = NULL, version = NULL,
solution = c(FALSE, FALSE, TRUE, FALSE, FALSE
), clozetype = NULL, points = 2, time = NULL,
shuffle = 5, length = 5L, string = "stat1_en_descriptive_stat_29: c",
maxchars = NULL, abstention = NULL, stringtype = NULL,
seed = 42982L), supplements = structure(character(0), names = character(0), dir = "/tmp/RtmpH83QPG/file8087677e29b/exam1/exercise3")),
exercise4 = list(question = c("\\emph{(4 \\myPoints)}",
"Q4"
), questionlist = c("A1", "A2","A3", "A4", "A5"), solution = NULL,
solutionlist = NULL, metainfo = list(file = "stat1_en_prob_8",
markup = "latex", type = "schoice", name = "stat1_en_prob_8",
title = NULL, section = NULL, version = NULL,
solution = c(FALSE, TRUE, FALSE, FALSE, FALSE
), clozetype = NULL, points = 4, time = NULL,
shuffle = 5, length = 5L, string = "stat1_en_prob_8: b",
maxchars = NULL, abstention = NULL, stringtype = NULL,
seed = 80660L), supplements = structure(c(stat1_en_descriptive_stat_20_1.png = "/tmp/RtmpH83QPG/file8087677e29b/exam1/exercise4/stat1_en_prob_8_1.png",
stat1_en_descriptive_stat_20_2.png = "/tmp/RtmpH83QPG/file8087677e29b/exam1/exercise4/stat1_en_prob_8_2.png"
), dir = "/tmp/RtmpH83QPG/file8087677e29b/exam1/exercise4")),
exercise5 = list(question = c("\\emph{(2 \\myPoints)}",
"Q5"
), questionlist = c("A1", "A2","A3", "A4", "A5"
), solution = NULL, solutionlist = NULL, metainfo = list(
file = "stat1_en_descriptive_stat_15", markup = "latex",
type = "schoice", name = "stat1_en_descriptive_stat_15",
title = NULL, section = NULL, version = NULL, solution = c(FALSE,
TRUE, FALSE, FALSE, FALSE), clozetype = NULL, points = 2,
time = NULL, shuffle = 5, length = 5L, string = "stat1_en_descriptive_stat_15: b",
maxchars = NULL, abstention = NULL, stringtype = NULL,
seed = 69316L), supplements = structure(character(0), names = character(0), dir = "/tmp/RtmpH83QPG/file8087677e29b/exam1/exercise5"))))
I want to make a psychometric analysis of each of the items (per exam). As such, I want to extract the names of the exercises per exam, and use them to merge the answers to all the items adequately.
For the first step I need to extract the information from this list as follows:
exams_list$`00001`$exercise1$metainfo$name
exams_list$`00001`$exercise2$metainfo$name
#...
exams_list$`00002`$exercise1$metainfo$name
exams_list$`00002`$exercise2$metainfo$name
I tried to use the purrr package but I was not successful. My goal is to end up with list of vectors; one vector per exame containing the names of the exercises.
CodePudding user response:
You can use a nested for() loop or nested sapply() for this:
sapply(exams_list, function(x) sapply(x, function(y) y$metainfo$name))
## 00001 00002
## exercise1 "stat1_en_descriptive_stat_34" "stat1_en_descriptive_stat_10"
## exercise2 "stat1_en_descriptive_stat_10" "stat1_en_descriptive_stat_34"
## exercise3 "stat1_en_descriptive_stat_15" "stat1_en_descriptive_stat_29"
## exercise4 "stat1_en_descriptive_stat_29" "stat1_en_prob_8"
## exercise5 "stat1_en_prob_8" "stat1_en_descriptive_stat_15"
The outer loop/apply is over the random replications (here 2), yielding the columns of the output. And the inner loop/apply is over the exercises in each replication (here 5), yielding the rows of the output.
From the matrix above you can obtain the necessary permutation to a desired order of the exercises, e.g., via match().
For the psychometric analysis I typically use the following workflow (using our own psychotools package).
## read nops evaluation output
x <- read.csv2("nops_eval.csv", dec = ".")
## select check columns and set 'not answered' to 'incorrect'
x <- as.matrix(x[, grep("^check\\.", names(x))])
x[is.na(x)] <- 0
## here you would have to apply the permutation and set nice colnames
## declare item-response matrix with itemresp class in psychotools
library("psychotools")
x <- itemresp(x)
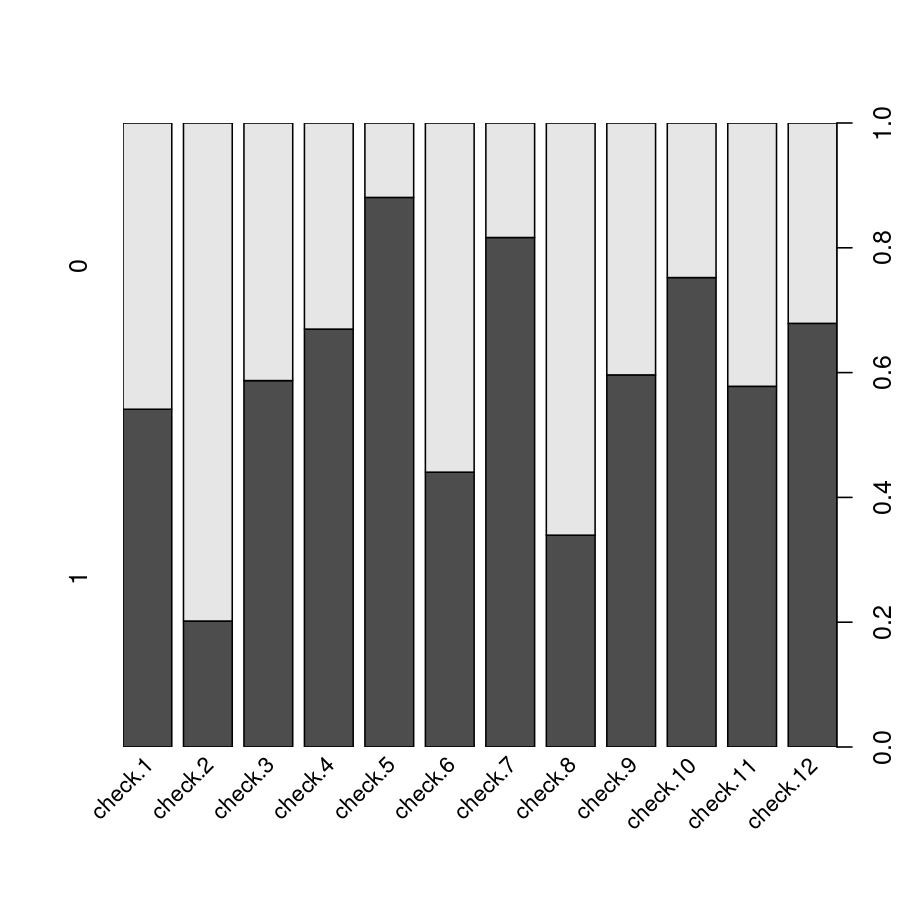
plot(x)
## fit basic Rasch model (via CML) and person-item map
m <- raschmodel(x)
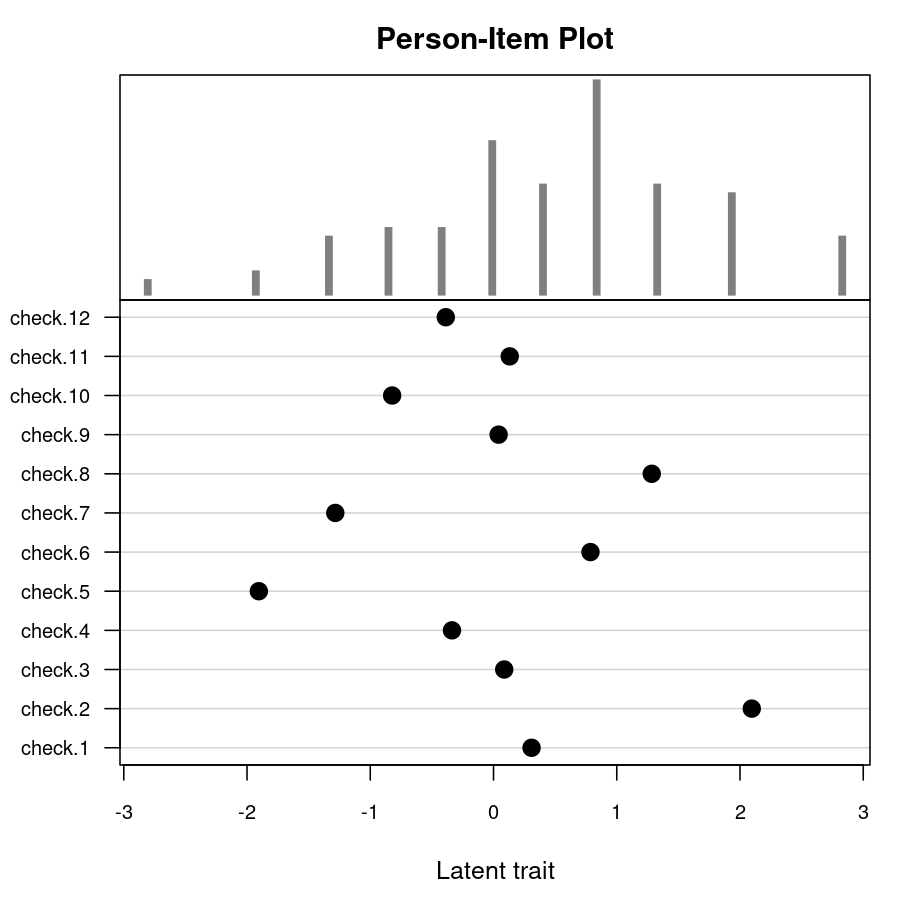
piplot(m)
| Stacked bar plot of raw frequencies | Person-item map for Rasch model |
|---|---|
 |
 |
For more refined analyses you might also be interested in these presentations: