I'm trying to retrieve the links of a Google Scholar user's work from their profile but am having trouble accessing the html that is hidden behind the "show more" button. I would like to be able to capture all the links from a user but currently can only get the first 20. Im using the following script to scrape for reference.
from bs4 import BeautifulSoup
import requests
author_url = 'https://scholar.google.com/citations?hl=en&user=mG4imMEAAAAJ'
html_content = requests.get(author_url)
soup = BeautifulSoup(html_content.text, 'lxml')
tables = soup.final_all('table)
table = tables[1]
rows = table.final_all('tr')
links = []
for row in rows:
t = row.find('a')
if t is not None:
links.append(t.get('href'))
CodePudding user response:
You need to use 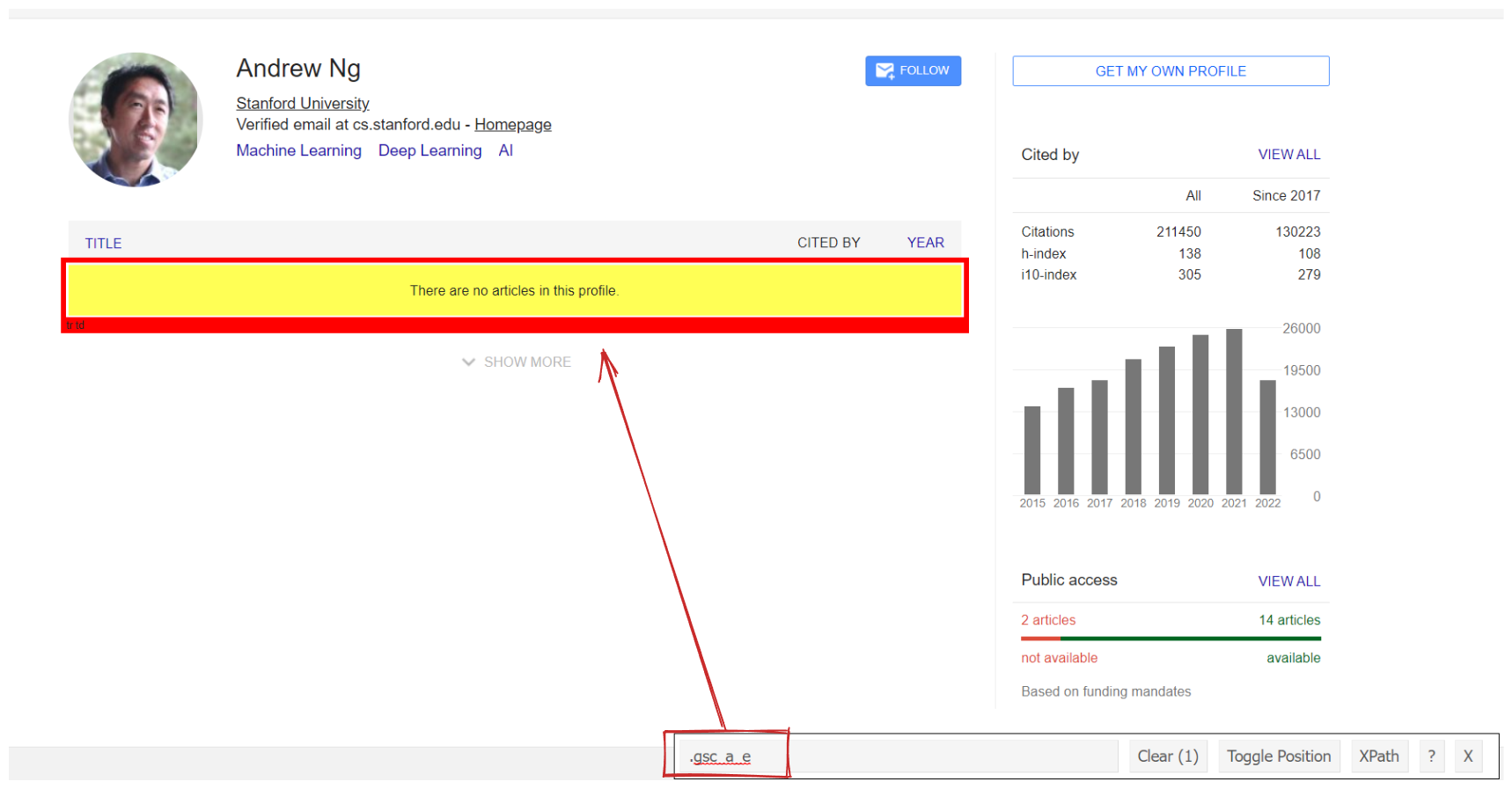
The great thing about such approach is that it paginates dynamically, instead of for i in range() which is hard coded and will be broken if certain authors have 20 articles and another has 2550 articles.
On the screenshot above I'm using the SelectorGadget Chrome extension that lets you pick CSS selectors by clicking on certain elements in the browser. It works great if the website is not heavily JS driven.
Keep in mind that at some point you also need to use CAPTCHA solver or proxies. This is only when you need to extract a lot of articles from multiple authors.
Code with the option to save to CSV using pandas and a full example in the online IDE:
import pandas as pd
from bs4 import BeautifulSoup
import requests, lxml, json
def bs4_scrape_articles():
params = {
"user": "mG4imMEAAAAJ", # user-id
"hl": "en", # language
"gl": "us", # country to search from
"cstart": 0, # articles page. 0 is the first page
"pagesize": "100" # articles per page
}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36"
}
all_articles = []
articles_is_present = True
while articles_is_present:
html = requests.post("https://scholar.google.com/citations", params=params, headers=headers, timeout=30)
soup = BeautifulSoup(html.text, "lxml")
for article in soup.select("#gsc_a_b .gsc_a_t"):
article_title = article.select_one(".gsc_a_at").text
article_link = f'https://scholar.google.com{article.select_one(".gsc_a_at")["href"]}'
article_authors = article.select_one(".gsc_a_at .gs_gray").text
article_publication = article.select_one(".gs_gray .gs_gray").text
all_articles.append({
"title": article_title,
"link": article_link,
"authors": article_authors,
"publication": article_publication
})
# this selector is checking for the .class that contains: "There are no articles in this profile."
# example link: https://scholar.google.com/citations?hl=en&user=mG4imMEAAAAJ&cstart=600
if soup.select_one(".gsc_a_e"):
articles_is_present = False
else:
params["cstart"] = 100 # paginate to the next page
print(json.dumps(all_articles, indent=2, ensure_ascii=False))
# pd.DataFrame(data=all_articles).to_csv(f"google_scholar_{params['user']}_articles.csv", encoding="utf-8", index=False)
bs4_scrape_articles()
Outputs (shows only last results as output is 400 articles):
[
{
"title": "Exponential family sparse coding with application to self-taught learning with text documents",
"link": "https://scholar.google.com/citations?view_op=view_citation&hl=en&user=mG4imMEAAAAJ&cstart=400&pagesize=100&citation_for_view=mG4imMEAAAAJ:LkGwnXOMwfcC",
"authors": "H Lee, R Raina, A Teichman, AY Ng",
"publication": ""
},
{
"title": "Visual and Range Data",
"link": "https://scholar.google.com/citations?view_op=view_citation&hl=en&user=mG4imMEAAAAJ&cstart=400&pagesize=100&citation_for_view=mG4imMEAAAAJ:eQOLeE2rZwMC",
"authors": "S Gould, P Baumstarck, M Quigley, AY Ng, D Koller",
"publication": ""
}
]
If you don't want want to deal with bypassing blocks from Google or maintaining your script, have a look at the Google Scholar Author Articles API.
There's also a scholarly package that can also extract author articles.
Code that shows how to extract all author articles with Google Scholar Author Articles API:
from serpapi import GoogleScholarSearch
from urllib.parse import urlsplit, parse_qsl
import pandas as pd
import os
def serpapi_scrape_articles():
params = {
# https://docs.python.org/3/library/os.html
"api_key": os.getenv("API_KEY"),
"engine": "google_scholar_author",
"hl": "en",
"author_id": "mG4imMEAAAAJ",
"start": "0",
"num": "100"
}
search = GoogleScholarSearch(params)
all_articles = []
articles_is_present = True
while articles_is_present:
results = search.get_dict()
for index, article in enumerate(results["articles"], start=1):
title = article["title"]
link = article["link"]
authors = article["authors"]
publication = article.get("publication")
citation_id = article["citation_id"]
all_articles.append({
"title": title,
"link": link,
"authors": authors,
"publication": publication,
"citation_id": citation_id
})
if "next" in results.get("serpapi_pagination", []):
# split URL in parts as a dict() and update "search" variable to a new page
search.params_dict.update(dict(parse_qsl(urlsplit(results["serpapi_pagination"]["next"]).query)))
else:
articles_is_present = False
print(json.dumps(all_articles, indent=2, ensure_ascii=False))
# pd.DataFrame(data=all_articles).to_csv(f"serpapi_google_scholar_{params['author_id']}_articles.csv", encoding="utf-8", index=False)
serpapi_scrape_articles()
CodePudding user response:
Here is one way of obtaining that data:
import requests
from bs4 import BeautifulSoup as bs
import pandas as pd
from tqdm import tqdm ## if Jupyter notebook: from tqdm.notebook import tqdm
pd.set_option('display.max_columns', None)
pd.set_option('display.max_colwidth', None)
big_df = pd.DataFrame()
headers = {
'accept-language': 'en-US,en;q=0.9',
'x-requested-with': 'XHR',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
}
s = requests.Session()
s.headers.update(headers)
payload = {'json': '1'}
for x in tqdm(range(0, 500, 100)):
url = f'https://scholar.google.com/citations?hl=en&user=mG4imMEAAAAJ&cstart={x}&pagesize=100'
r = s.post(url, data=payload)
soup = bs(r.json()['B'], 'html.parser')
works = [(x.get_text(), 'https://scholar.google.com' x.get('href')) for x in soup.select('a') if 'javascript:void(0)' not in x.get('href') and len(x.get_text()) > 7]
df = pd.DataFrame(works, columns = ['Paper', 'Link'])
big_df = pd.concat([big_df, df], axis=0, ignore_index=True)
print(big_df)
Result in terminal:
100%
5/5 [00:03<00:00, 1.76it/s]
Paper Link
0 Latent dirichlet allocation https://scholar.google.com/citations?view_op=view_citation&hl=en&user=mG4imMEAAAAJ&pagesize=100&citation_for_view=mG4imMEAAAAJ:IUKN3-7HHlwC
1 On spectral clustering: Analysis and an algorithm https://scholar.google.com/citations?view_op=view_citation&hl=en&user=mG4imMEAAAAJ&pagesize=100&citation_for_view=mG4imMEAAAAJ:2KloaMYe4IUC
2 ROS: an open-source Robot Operating System https://scholar.google.com/citations?view_op=view_citation&hl=en&user=mG4imMEAAAAJ&pagesize=100&citation_for_view=mG4imMEAAAAJ:u-x6o8ySG0sC
3 Rectifier nonlinearities improve neural network acoustic models https://scholar.google.com/citations?view_op=view_citation&hl=en&user=mG4imMEAAAAJ&pagesize=100&citation_for_view=mG4imMEAAAAJ:gsN89kCJA0AC
4 Recursive deep models for semantic compositionality over a sentiment treebank https://scholar.google.com/citations?view_op=view_citation&hl=en&user=mG4imMEAAAAJ&pagesize=100&citation_for_view=mG4imMEAAAAJ:_axFR9aDTf0C
... ... ...
473 A Sparse Sampling Algorithm for Near-Optimal Planning in Large Markov Decision Processes https://scholar.google.com/citations?view_op=view_citation&hl=en&user=mG4imMEAAAAJ&cstart=400&pagesize=100&citation_for_view=mG4imMEAAAAJ:hMod-77fHWUC
474 On Discrim inative vs. Generative https://scholar.google.com/citations?view_op=view_citation&hl=en&user=mG4imMEAAAAJ&cstart=400&pagesize=100&citation_for_view=mG4imMEAAAAJ:qxL8FJ1GzNcC
475 Game Theory with Restricted Strategies https://scholar.google.com/citations?view_op=view_citation&hl=en&user=mG4imMEAAAAJ&cstart=400&pagesize=100&citation_for_view=mG4imMEAAAAJ:8k81kl-MbHgC
476 Exponential family sparse coding with application to self-taught learning with text documents https://scholar.google.com/citations?view_op=view_citation&hl=en&user=mG4imMEAAAAJ&cstart=400&pagesize=100&citation_for_view=mG4imMEAAAAJ:LkGwnXOMwfcC
477 Visual and Range Data https://scholar.google.com/citations?view_op=view_citation&hl=en&user=mG4imMEAAAAJ&cstart=400&pagesize=100&citation_for_view=mG4imMEAAAAJ:eQOLeE2rZwMC
478 rows × 2 columns
See pandas documentation at https://pandas.pydata.org/docs/
Also Requests docs: https://requests.readthedocs.io/en/latest/
For BeautifulSoup, go to https://beautiful-soup-4.readthedocs.io/en/latest/
And for TQDM visit https://pypi.org/project/tqdm/