List item
I am new to web scrapping and after a couple of Wikipedia pages I found this page where I wanted to extract the tables for all the portfolio managers. I am not able to use the things I found on the internet. I thought it would be easy since it's just a table but I am not able to extract even a single table after filling out the form. Can someone please tell me how I could get this done in R? I have added an image in this post but it seems to look like a link that says to enter image description here.
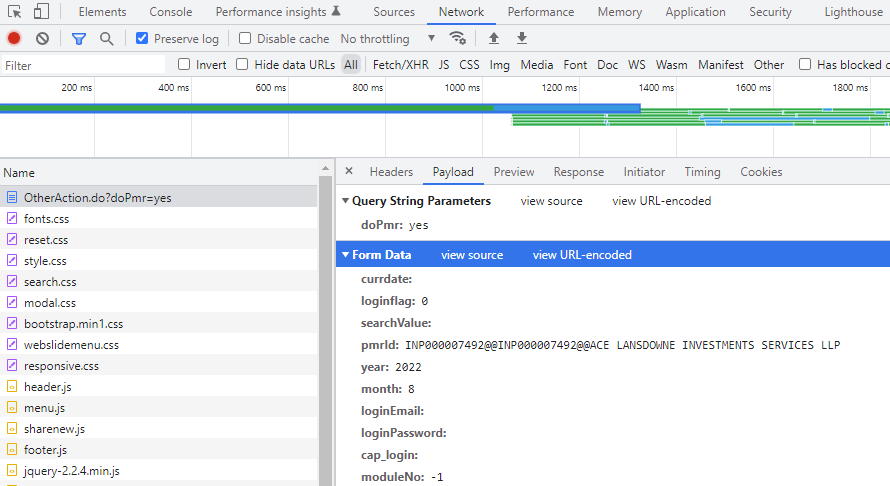
Lazy approach would be just using Copy as cURL in DevTools and heading to https://curlconverter.com/r/ to convert it to httr request.
library(rvest)
resp <- httr::POST("https://www.sebi.gov.in/sebiweb/other/OtherAction.do?doPmr=yes",
body = list(
pmrId="INP000004417@@INP000004417@@AEQUITAS INVESTMENT CONSULTANCY PRIVATE LIMITED",
year="2022",
month="8"))
tables <- resp %>%
read_html() %>%
html_elements("table") %>%
html_table()
# first table:
tables[[1]]
#> # A tibble: 11 × 2
#> X1 X2
#> <chr> <chr>
#> 1 Name of the Portfolio Manager "Aeq…
#> 2 Registration Number "INP…
#> 3 Date of Registration "201…
#> 4 Registered Address of the Portfolio Manager ",,,…
#> 5 Name of Principal Officer ""
#> 6 Email ID of the Principal Officer ""
#> 7 Contact Number (Direct) of the Principal Officer ""
#> 8 Name of Compliance Officer ""
#> 9 Email ID of the Compliance Officer ""
#> 10 No. of clients as on last day of the month "124…
#> 11 Total Assets under Management (AUM) as on last day of the month (Amoun… "143…
Created on 2022-10-11 with reprex v2.0.2