Trying to create a table in Pyspark in Databricks which would capture database name, table name and DDL statement for each table. Hive metastore has been loaded in AzureMySQL on which Databricks cluster is pointing. While in separate dataframe objects I am able to capture needed details, however unable to combine them into one single table. Schema I am looking at : DatabaseName, TableName, CreateDDLStatement, Location. For database name and table name here is the dataframe df1
tables = spark.catalog.listTables(db)
for t in tables:
Df1 = spark.sql("show tables in db1")
Df1.createOrReplaceTempView("TempTable1")
result1 = sqlContext.sql('select * from TempTable1')
result1.show()
Output -
DatabaseName TableName IsTemporary
db1 tb1 False
db2 tb2 True db = "db1"
tables = spark.catalog.listTables(db)
for t in tables:
Df1 = spark.sql("show tables in db1")
Df1.createOrReplaceTempView("TempTable1")
result1 = sqlContext.sql('select * from TempTable1')
result1.show()
Output -
DatabaseName TableName IsTemporary
db1 tb1 False
db2 tb2 True
Second dataframe objects has DDL statement for each table
for t in tables:
DF2 = spark.sql("SHOW CREATE TABLE {}.{}".format(db, t.name))
DF2.createOrReplaceTempView("TempTable2")
result2 = sqlContext.sql('select * from TempTable2')
result2.show(10)
crtmnt_stmnt
create table tb1....
create table tb2
Expected Output
DatabaseName TableName IsTemporary crtmnt_stmnt
db1 tb1 False create table tb1...
db2 tb2 True create table tb2...
Can I append a column to dataframe object or temporary table. how to dynamically take values using withColumn and spark.sql command
CodePudding user response:
Since you already have a Dataframe where you have database and table name (which are used while create crtmnt_stmnt column), you can achieve this with dataframes itself.
- The following is the dataframe I have using code similar to yours:
df1= spark.sql("show tables in default")
df1.createOrReplaceTempView("default.temp_table")
result = spark.sql("select * from temp_table")
result.show()
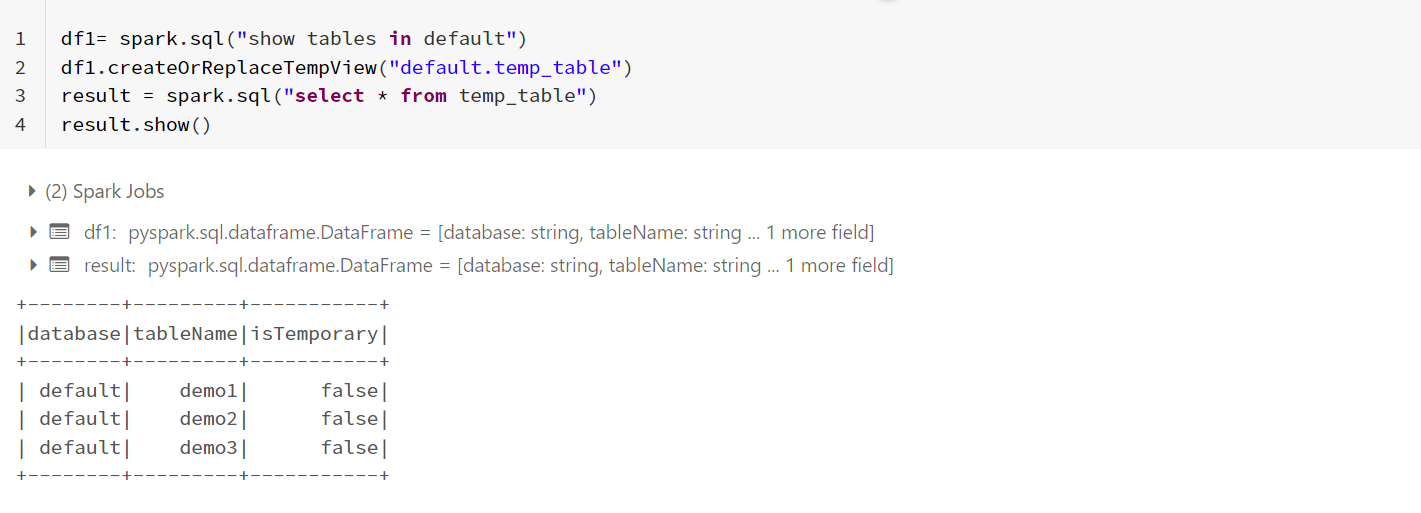
Now, I have created a dataframe that has all the details required. Iterating through
tables, I created a temporary dataframe which I am appending to my final dataframe. I have also added 2 columns while doing so i.e.,tablename and databaseusingwithColumn.This is because we will have key columns in our final dataframe(create statement dataframe) using which we can apply inner join on the above df1.
from pyspark.sql.functions import col,lit,concat
df2=None
db='default'
for t in tables:
if(df2 is None):
df2 = spark.sql("SHOW CREATE TABLE {}.{}".format(db, t.name))
df2 = df2.withColumn("table_name",lit(t.name)).withColumn("db_name",lit(db))
else:
temp = spark.sql("SHOW CREATE TABLE {}.{}".format(db, t.name))
temp = temp.withColumn("table_name",lit(t.name)).withColumn("db_name",lit(db))
df2 = df2.union(temp)
df2.createOrReplaceTempView("create_table")
#display(df2)
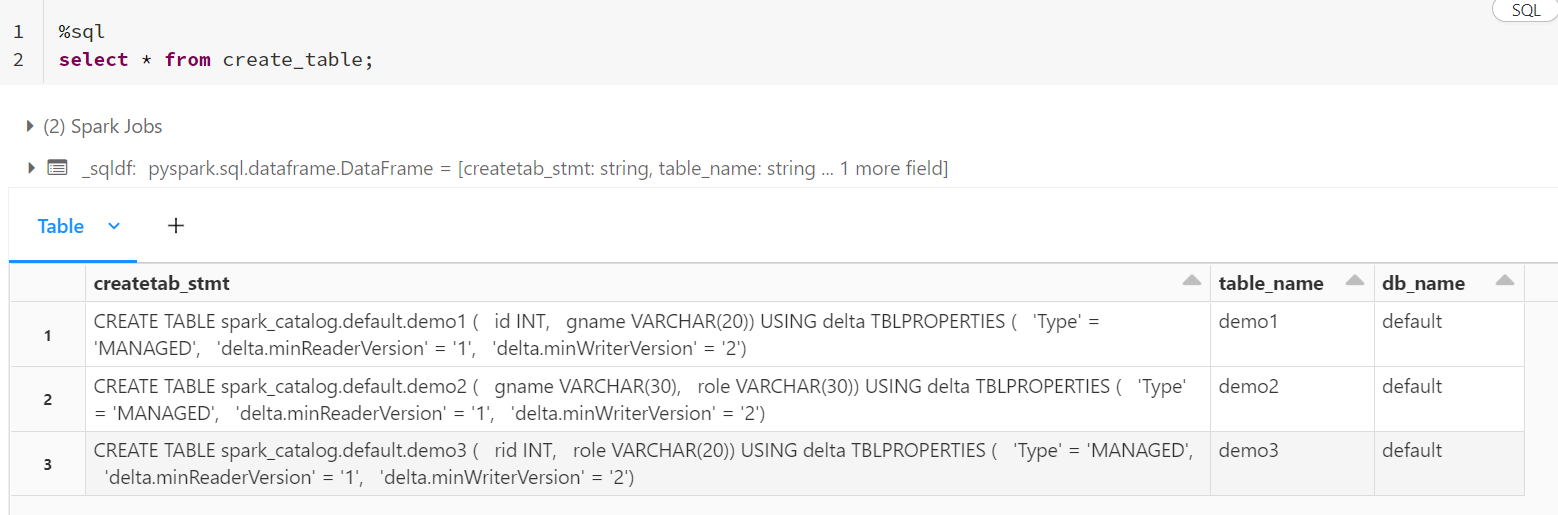
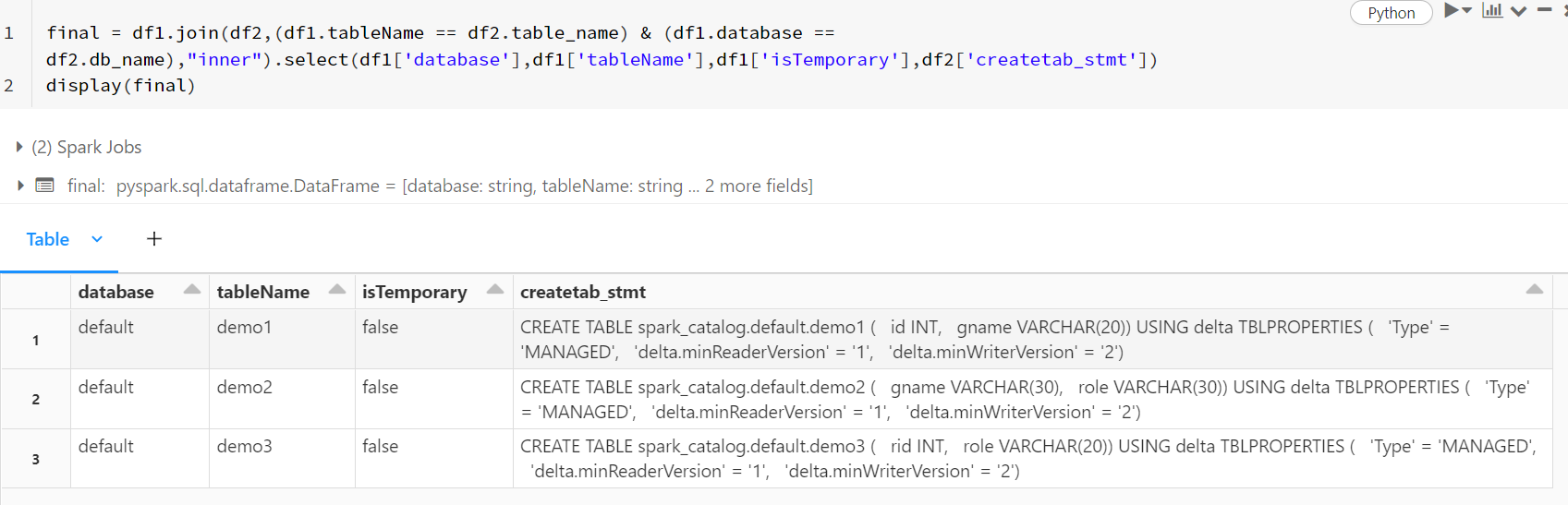
- I have used pyspark to apply inner join to get the desired result.
final = df1.join(df2,(df1.tableName == df2.table_name) & (df1.database == df2.db_name),"inner").select(df1['database'],df1['tableName'],df1['isTemporary'],df2['createtab_stmt'])
display(final)
- Using
spark.sql()the code would be as follows (using the temporary views created)
spark.sql("select d1.database,d1.tableName,d1.isTemporary,d2.createtab_stmt from temp_table d1 inner join create_table d2 on d1.database=d2.db_name and d1.tableName=d2.table_name").show()