My DataFrame looks like this:
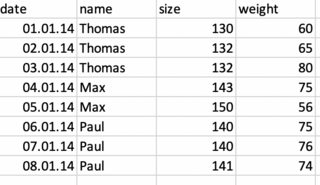
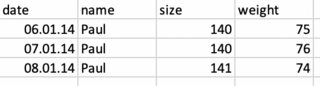
What I would like to do is: if weight is once less than 70, drop all rows that have the same name. So, if Thomas' weight was once less than 70, drop all his data and repeat this for all the other names. So in my case the result would be:
Code to rebuild data:
data = {'date': {0: Timestamp('2014-01-01 00:00:00'),
1: Timestamp('2014-01-02 00:00:00'),
2: Timestamp('2014-01-03 00:00:00'),
3: Timestamp('2014-01-04 00:00:00'),
4: Timestamp('2014-01-05 00:00:00'),
5: Timestamp('2014-01-06 00:00:00'),
6: Timestamp('2014-01-07 00:00:00'),
7: Timestamp('2014-01-08 00:00:00')},
'name': {0: 'Thomas', 1: 'Thomas', 2: 'Thomas', 3: 'Max',
4: 'Max', 5: 'Paul', 6: 'Paul', 7: 'Paul'},
'size': {0: 130, 1: 132, 2: 132, 3: 143, 4: 150, 5: 140,
6: 140, 7: 141},
'weight': {0: 60, 1: 65, 2: 80, 3: 75, 4: 56, 5: 75, 6: 76, 7: 74}}
df = pd.DataFrame(data)
CodePudding user response:
names = list(df[df['weight']<70]['name'])
df_new = df[~(df['name'].isin(names))]
CodePudding user response:
Try as follows:
- Select column
namefrom thedfbased onSeries.ltand turn into a list withSeries.tolist. Feed the resulting list toSeries.isinand combine with unary operator (~) for selection from thedf.
res = df[~df.name.isin(df[df.weight.lt(70)].name.tolist())]
print(res)
date name size weight
5 2014-01-06 Paul 140 75
6 2014-01-07 Paul 140 76
7 2014-01-08 Paul 141 74
Or as a variant on this answer to a similar question, try as follows:
- Use
df.groupbyon columnnameand applyfilterwith a lambda function, keeping the group only ifSeries.geisTrueforallits values.
res = df.groupby('name').filter(lambda x: x.weight.ge(70).all())
# same result