I have a bytestream that would like to read into the Python. I would like to use Pandas to hold the data. For example:
bytestream = '000102030404'
First I need to split the bytestream into different rows, with fixed size (2 bytes in this example).
bytestreamArray = ['0001', '0203', '0404']
Then I would like to split the array into two different columns
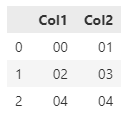
| Col1 | Col2 |
|---|---|
| 00 | 01 |
| 02 | 03 |
| 04 | 04 |
I wonder if I could do all in Pandas? Or I need to split the row in Python first then process it in Pandas?
Thanks in advance
CodePudding user response:
You could use regex to find the pattern:
r'(\d\d)(\d\d)'
The (\d\d) looks for two digits, and assigns them to a group. I included the search for two groups to make it easier for what you were trying to do.
I then use the output from the findall() function to generate a dataframe.
Here is the code:
import re
import pandas as pd
bytestream = '000102030404'
pattern = re.compile(r'(\d\d)(\d\d)')
byte_rows = re.findall(pattern, bytestream)
df = pd.DataFrame(byte_rows, columns=["Col1", "Col2"])
The Dataframe (df) looks like this: