I'm trying to inspect the behaviour of the pandas.DataFrame.groupby and pandas.DataFrame.pivot_table methods and I've come up to this difference which I can't explain by myself.
It seems that the specification of dropna=True (default for both) has different consequences in the two cases, which might be somehow enforced by the different descriptions which are given within the docs.
For 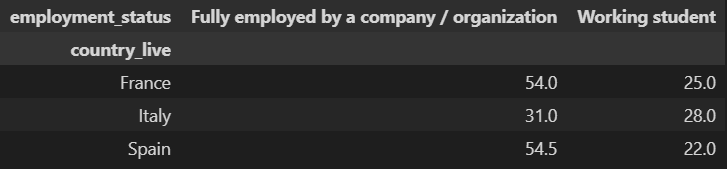
With .groupby() I'd instead get (while expecting the same result obtained above):
df.groupby(by=['country_live', 'employment_status'], dropna=True)['age'] \
.mean() \
.unstack()

Can someone explain the reason(s) why the two do not work the same (thus implicitly explaining the behaviour of dropna in .groupby())?
CodePudding user response:
Replying to your comment here since code formatting is a pain in comments.
I don't know exactly how you tried dropna=False for groupby, but running the following code will show the group with nan value for country_live:
df = pd.DataFrame({
'age': [31, np.nan, 28, 22, 54, np.nan, 49, 60, 25, np.nan],
'country_live': ['Italy', pd.NA, 'Italy', 'Spain', 'France', 'Italy', 'Spain', 'Spain', 'France', 'Spain'],
'employment_status': ['Fully employed by a company / organization', 'Partially employed by a company / organization',
'Working student', 'Working student', 'Fully employed by a company / organization', 'Partially employed by a company / organization',
'Fully employed by a company / organization', 'Fully employed by a company / organization', 'Working student',
'Partially employed by a company / organization']
},
)
df = df.assign(age=lambda t: t['age'].astype('Int64'), \
country_live=lambda t: t['country_live'].astype('category'), \
employment_status=lambda t: t['employment_status'].astype('category'))
for gp, sub_df in df.groupby(by=['country_live', 'employment_status'], dropna=False):
print(gp, sub_df, "\n", sep="\n")
Output (see last lines):
('France', 'Fully employed by a company / organization')
age country_live employment_status
4 54 France Fully employed by a company / organization
('France', 'Working student')
age country_live employment_status
8 25 France Working student
('Italy', 'Fully employed by a company / organization')
age country_live employment_status
0 31 Italy Fully employed by a company / organization
('Italy', 'Partially employed by a company / organization')
age country_live employment_status
5 <NA> Italy Partially employed by a company / organization
('Italy', 'Working student')
age country_live employment_status
2 28 Italy Working student
('Spain', 'Fully employed by a company / organization')
age country_live employment_status
6 49 Spain Fully employed by a company / organization
7 60 Spain Fully employed by a company / organization
('Spain', 'Partially employed by a company / organization')
age country_live employment_status
9 <NA> Spain Partially employed by a company / organization
('Spain', 'Working student')
age country_live employment_status
3 22 Spain Working student
(nan, 'Partially employed by a company / organization')
age country_live employment_status
1 <NA> NaN Partially employed by a company / organization
Respectively, the nan group will be ignored if you set dropna=True
CodePudding user response:
The main difference is that for .groupby() the dropna=True refers to the groups you are creating, NOT to the values. In fact if you add a row to your df:
row = {'age':50,'country_live':np.nan,'employment_status':'Partially employed by a company / organization'}
df = df.append(row, ignore_index=True)
the pivot table does not change the output changing the bool of dropna (you don't have the nan group in the index.
The situation changes in the groupby:
With dropna=True you have the same result you obtained, with dropna=False, the nan group is added