I am developing my ANN from scratch which is supposed to classify 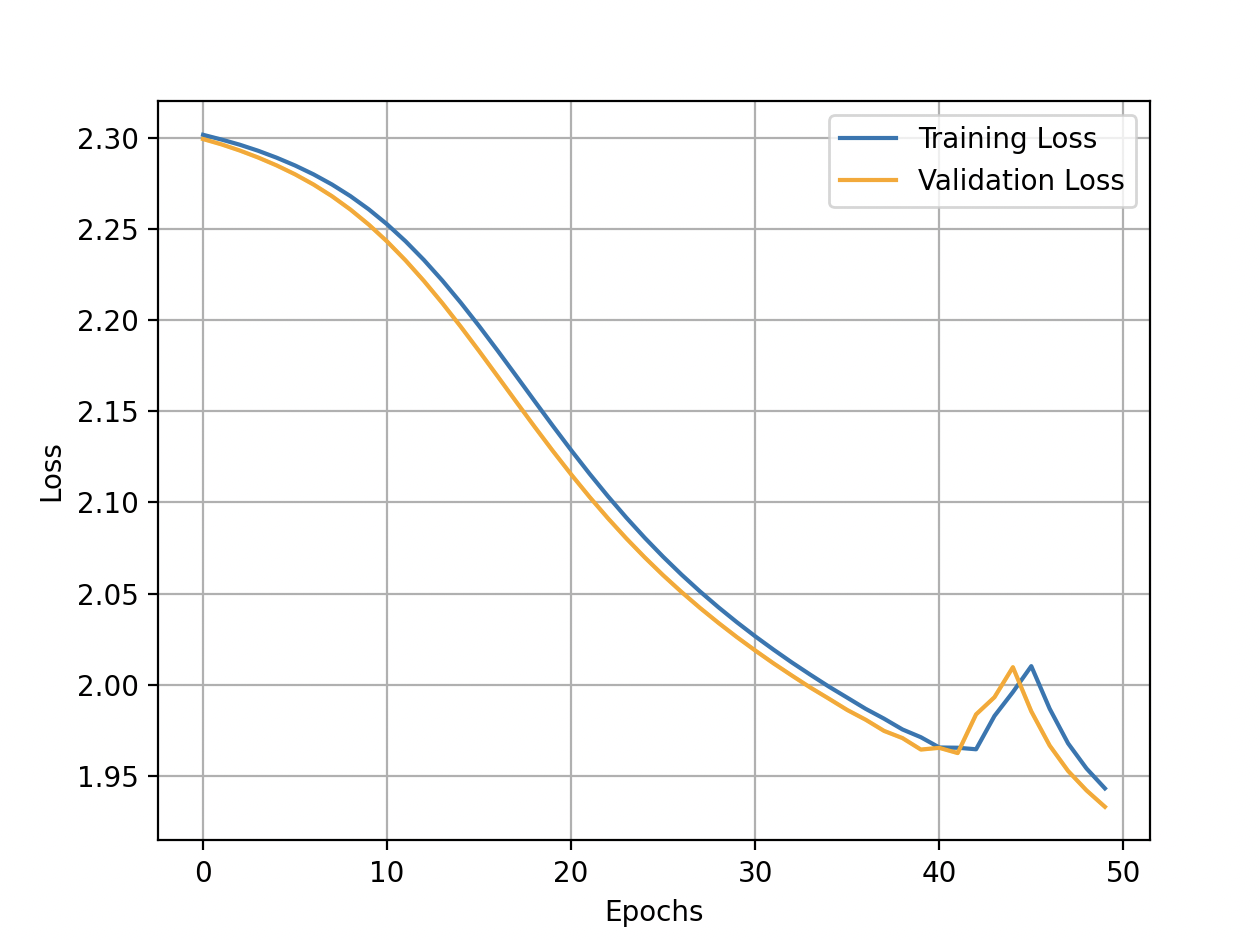
As you can see when momentum=0 my learning rule is the (vanilla) gradient descent. Unfortunately when I set momentum=0.9 (or any other value), the learning seems not the work properly:
E(0) train_loss: 2.302783139685314 val_loss: 2.2992788953305396 val_acc: 19.950000000000003 %
E(1) train_loss: 2.2993850383518213 val_loss: 2.2848443220743024 val_acc: 20.979999999999997 %
E(2) train_loss: 2.2852413073649185 val_loss: 2.2245098593332324 val_acc: 24.29 %
E(3) train_loss: 2.2256566385909484 val_loss: 2.052373637528151 val_acc: 34.74 %
E(4) train_loss: 2.054457510557211 val_loss: 1.7725185209449252 val_acc: 38.74 %
E(5) train_loss: 1.7750945816727548 val_loss: 4.766960950639445 val_acc: 23.73 %
...
E(20) train_loss: 629.5534744116509 val_loss: 629.269795928194 val_acc: 11.27 %
E(21) train_loss: 629.5534744116509 val_loss: 629.269795928194 val_acc: 11.27 %
E(22) train_loss: 629.5534744116509 val_loss: 629.269795928194 val_acc: 11.27 %
E(23) train_loss: 629.5534744116509 val_loss: 629.269795928194 val_acc: 11.27 %
E(24) train_loss: 629.5534744116509 val_loss: 629.269795928194 val_acc: 11.27 %
E(25) train_loss: 629.5534744116509 val_loss: 629.269795928194 val_acc: 11.27 %
E(26) train_loss: 629.5534744116509 val_loss: 629.269795928194 val_acc: 11.27 %
E(27) train_loss: 629.5534744116509 val_loss: 629.269795928194 val_acc: 11.27 %
E(28) train_loss: 629.5534744116509 val_loss: 629.269795928194 val_acc: 11.27 %
E(29) train_loss: 629.5534744116509 val_loss: 629.269795928194 val_acc: 11.27 %
E(30) train_loss: 629.5534744116509 val_loss: 629.269795928194 val_acc: 11.27 %
...
E(49) train_loss: 629.5534744116509 val_loss: 629.269795928194 val_acc: 11.27 %
Validation loss is minimum at epoch 4
Accuracy score on test set is: 11.360000000000001 %
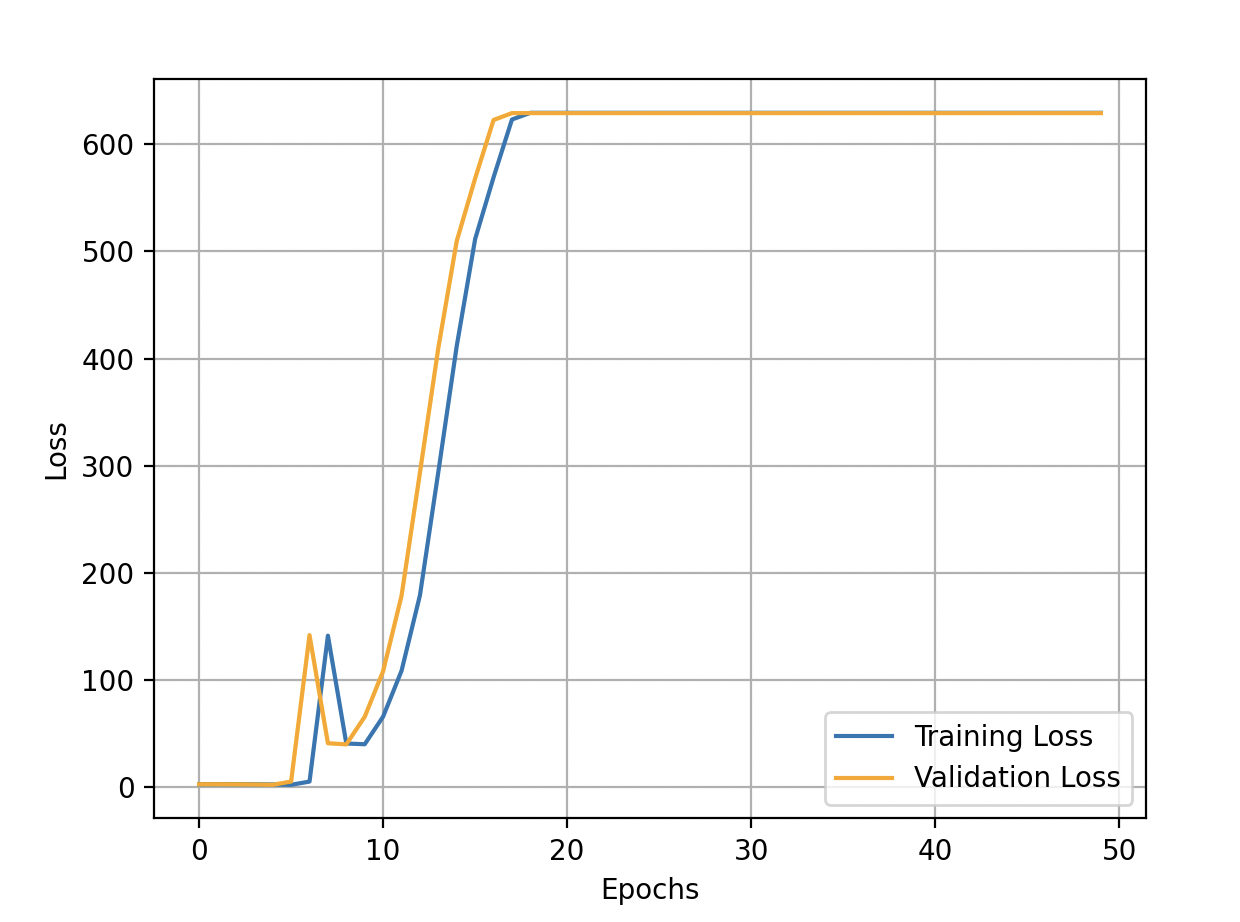
What am I missing? What's the problem? The Gradient Descent with momentum formula is:

This is my code:
from mnist.loader import MNIST
from sklearn.utils import shuffle
import numpy as np
def accuracy_score(targets, predictions):
predictions = softmax(predictions)
correct_predictions = 0
for item in range(np.shape(predictions)[1]):
argmax_idx = np.argmax(predictions[:, item])
if targets[argmax_idx, item] == 1:
correct_predictions = 1
return correct_predictions / np.shape(predictions)[1]
def one_hot(targets):
return np.asmatrix(np.eye(10)[targets]).T
def plot(epochs, loss_train, loss_val):
plt.plot(epochs, loss_train)
plt.plot(epochs, loss_val, color="orange")
plt.legend(["Training Loss", "Validation Loss"])
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.grid(True)
plt.show()
def identity(a, derivative=False):
f_a = a
if derivative:
return np.ones(np.shape(a))
return f_a
def relu(a, derivative=False):
f_a = np.maximum(0, a)
if derivative:
return (a > 0) * 1
return f_a
def softmax(y):
epsilon = 10 ** -308
e_y = np.exp(y - np.max(y, axis=0))
sm = e_y / np.sum(e_y, axis=0)
return np.clip(sm, epsilon, 1 - epsilon)
def cross_entropy(y, t, derivative=False, post_process=True):
if post_process:
if derivative:
return y - t
sm = softmax(y)
item_loss = -np.sum(np.multiply(t, np.log(sm)), axis=0)
return np.mean(item_loss)
class NeuralNetwork:
def __init__(self):
self.layers = []
def add(self, layer):
self.layers.append(layer)
def build(self):
for i, layer in enumerate(self.layers):
if i == 0:
layer.type = "input"
else:
layer.type = "output" if i == len(self.layers) - 1 else "hidden"
layer.configure(self.layers[i - 1].neurons)
def fit(self, X_train, targets_train, X_val, targets_val, max_epochs=50):
e_loss_train = []
e_loss_val = []
# Getting the minimum loss on validation set
predictions_val = self.predict(X_val)
min_loss_val = cross_entropy(predictions_val, targets_val)
best_net = self # net which minimize validation loss
best_epoch = 0 # epoch where the validation loss is minimum
# batch mode
for epoch in range(max_epochs):
predictions_train = self.predict(X_train)
self.back_prop(targets_train, cross_entropy)
self.learning_rule(l_rate=0.000005, momentum=0.9)
loss_train = cross_entropy(predictions_train, targets_train)
e_loss_train.append(loss_train)
# Validation
predictions_val = self.predict(X_val)
loss_val = cross_entropy(predictions_val, targets_val)
e_loss_val.append(loss_val)
print(f"E({epoch}) "
f"train_loss: {loss_train} "
f"val_loss: {loss_val} "
f"val_acc: {accuracy_score(targets_val, predictions_val) * 100} %")
if loss_val < min_loss_val:
min_loss_val = loss_val
best_epoch = epoch
best_net = self
print(f"Validation loss is minimum at epoch {best_epoch}")
plot(np.arange(max_epochs), e_loss_train, e_loss_val)
return best_net
# Matrix of predictions where the i-th column corresponds to the i-th item
def predict(self, dataset):
z = dataset
for layer in self.layers:
z = layer.forward_prop_step(z)
return z
def back_prop(self, target, loss):
for i, layer in enumerate(self.layers[:0:-1]):
next_layer = self.layers[-i]
prev_layer = self.layers[-i - 2]
layer.back_prop_step(next_layer, prev_layer, target, loss)
def learning_rule(self, l_rate, momentum):
# Momentum GD
for layer in [layer for layer in self.layers if layer.type != "input"]:
layer.update_weights(l_rate, momentum)
layer.update_bias(l_rate, momentum)
class Layer:
def __init__(self, neurons, type=None, activation=None):
self.dE_dW = None # derivatives dE/dW where W is the weights matrix
self.dE_db = None # derivatives dE/db where b is the bias
self.dact_a = None # derivative of the activation function
self.out = None # layer output
self.weights = None # input weights
self.bias = None # layer bias
self.w_sum = None # weighted_sum
self.neurons = neurons # number of neurons
self.type = type # input, hidden or output
self.activation = activation # activation function
self.deltas = None # for back-prop
self.diff_w = None # for momentum
self.diff_b = None # for momentum
def configure(self, prev_layer_neurons):
self.set_activation()
self.weights = np.asmatrix(np.random.uniform(-0.02, 0.02, (self.neurons, prev_layer_neurons)))
self.bias = np.asmatrix(np.random.uniform(-0.02, 0.02, self.neurons)).T
self.diff_w = np.asmatrix(np.zeros(shape=np.shape(self.weights)))
self.diff_b = np.asmatrix(np.zeros(shape=np.shape(self.bias)))
def set_activation(self):
if self.activation is None:
if self.type == "hidden":
self.activation = relu
elif self.type == "output":
self.activation = identity
def forward_prop_step(self, z):
if self.type == "input":
self.out = z
else:
self.w_sum = np.dot(self.weights, z) self.bias
self.out = self.activation(self.w_sum)
return self.out
def back_prop_step(self, next_layer, prev_layer, target, local_loss):
if self.type == "output":
self.dact_a = self.activation(self.w_sum, derivative=True)
self.deltas = np.multiply(self.dact_a,
local_loss(self.out, target, derivative=True))
else:
self.dact_a = self.activation(self.w_sum, derivative=True) # (m,batch_size)
self.deltas = np.multiply(self.dact_a, np.dot(next_layer.weights.T, next_layer.deltas))
self.dE_dW = self.deltas * prev_layer.out.T
self.dE_db = np.sum(self.deltas, axis=1)
def update_weights(self, l_rate, momentum):
self.weights = self.weights - l_rate * self.dE_dW momentum * self.diff_w
self.diff_w = np.copy(self.weights)
# Vanilla GD
# self.weights = self.weights - l_rate * self.dE_dW
def update_bias(self, l_rate, momentum):
self.bias = self.bias - l_rate * self.dE_db momentum * self.diff_b
self.diff_b = np.copy(self.bias)
# Vanilla GD
# self.bias = self.bias - l_rate * self.dE_db
if __name__ == '__main__':
mndata = MNIST(path="data", return_type="numpy")
X_train, targets_train = mndata.load_training() # 60.000 images, 28*28 features
X_test, targets_test = mndata.load_testing() # 10.000 images, 28*28 features
X_train, targets_train = shuffle(X_train, targets_train.T)
# Data pre processing
X_train = X_train / 255 # normalization within [0;1]
X_test = X_test / 255 # normalization within [0;1]
X_train = X_train.T # data transposition
X_test = X_test.T # data transposition
# Split
X_val, X_train = np.hsplit(X_train, [10000])
targets_val, targets_train = np.hsplit(targets_train, [10000])
# One hot
targets_train = one_hot(targets_train)
targets_val = one_hot(targets_val)
targets_test = one_hot(targets_test)
net = NeuralNetwork()
d = np.shape(X_train)[0] # number of features, 28x28
c = np.shape(targets_train)[0] # number of classes, 10
# Net creation
for m in (d, 100, c):
net.add(Layer(m))
net.build()
best_net = net.fit(X_train, targets_train, X_val, targets_val, max_epochs=50)
# Testing
predictions_test = best_net.predict(X_test)
accuracy_test = accuracy_score(targets_test, predictions_test)
print(f"Accuracy score on test set is: {accuracy_test * 100} %")
CodePudding user response:
As mentioned by @xdurch0 the update rule is invalid
def update_weights(self, l_rate, momentum):
self.weights = self.weights - l_rate * self.dE_dW momentum * self.diff_w
self.diff_w = np.copy(self.weights)
def update_bias(self, l_rate, momentum):
self.bias = self.bias - l_rate * self.dE_db momentum * self.diff_b
self.diff_b = np.copy(self.bias)
should be
def update_weights(self, l_rate, momentum):
self.diff_w = l_rate * self.dE_dW momentum * self.diff_w
self.weights = self.weights - self.diff_w
def update_bias(self, l_rate, momentum):
self.diff_b = l_rate * self.dE_db momentum * self.diff_b
self.bias = self.bias - self.diff_b
Momentum means "apply the previous update" again, with slowly decaying factor in front of it.