I don't know why my .replace wont advance to the next value in my for loop.
Code:
import pandas as pd
import numpy as np
df1 = pd.read_csv("df1.csv")
df2 = pd.read_csv("df2.csv")
print(df1)
print(df2)
df3 = pd.merge(df1, df2, on='ID', how='left')
print(df3)
C = len(df3.index)
for i in range(C):
if pd.isnull(df3.at[i, 'Leg']) == True:
df3.replace((df3.at[i, 'Leg']), (df3.at[i, 'ID']), inplace=True)
df3.replace((df3.at[i, 'SAP']), (df3.at[i, 'ID']), inplace=True)
print(df3)
Result:
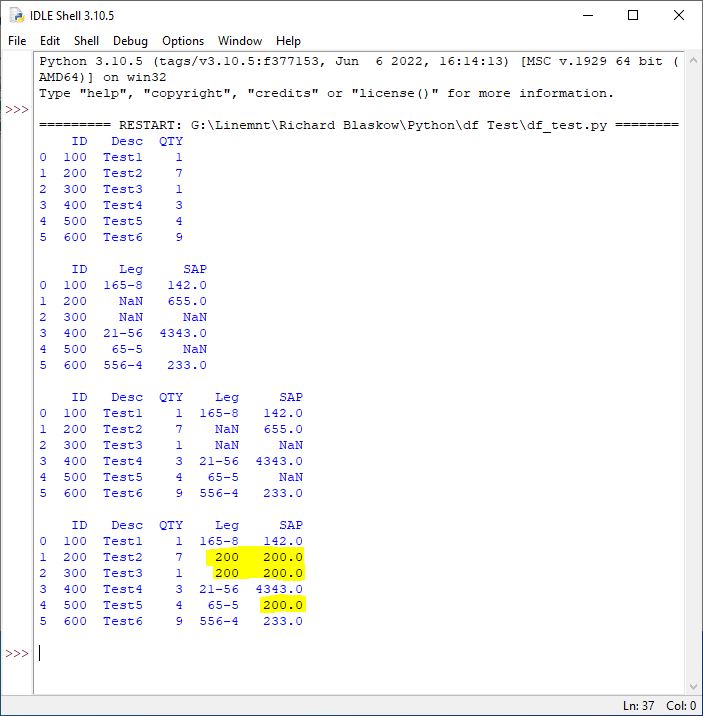
My replaced values in the 'Leg' and 'SAP' columns don't advance with my for loop. I want any NaN values to read the same as the corresponding value in the 'ID' column. Without changing any other values in any other columns.
Image as Text:
ID Desc QTY
0 100 Test1 1
1 200 Test2 7
2 300 Test3 1
3 400 Test4 3
4 500 Test5 4
5 600 Test6 9
ID Leg SAP
0 100 165-8 142.0
1 200 NaN 655.0
2 300 NaN NaN
3 400 21-56 4343.0
4 500 65-5 NaN
5 600 556-4 233.0
ID Desc QTY Leg SAP
0 100 Test1 1 165-8 142.0
1 200 Test2 7 NaN 655.0
2 300 Test3 1 NaN NaN
3 400 Test4 3 21-56 4343.0
4 500 Test5 4 65-5 NaN
5 600 Test6 9 556-4 233.0
ID Desc QTY Leg SAP
0 100 Test1 1 165-8 142.0
1 200 Test2 7 200 200.0
2 300 Test3 1 200 200.0
3 400 Test4 3 21-56 4343.0
4 500 Test5 4 65-5 200.0
5 600 Test6 9 556-4 233.0
Expected Result:
ID Desc QTY Leg SAP
0 100 Test1 1 165-8 142.0
1 200 Test2 7 200 655.0
2 300 Test3 1 300 300.0
3 400 Test4 3 21-56 4343.0
4 500 Test5 4 65-5 500.0
5 600 Test6 9 556-4 233.0
CodePudding user response:
You can try:
df3["Leg"] = df3["Leg"].combine_first(df3["ID"])
df3["SAP"] = df3["SAP"].combine_first(df3["ID"])
print(df3)
Prints:
ID Desc QTY Leg SAP
0 100 Test1 1 165-8 142.0
1 200 Test2 7 200 655.0
2 300 Test3 1 300 300.0
3 400 Test4 3 21-56 4343.0
4 500 Test5 4 65-5 500.0
5 600 Test6 9 556-4 233.0
Or:
df3[["Leg", "SAP"]] = (
df3[["ID", "Leg", "ID", "SAP"]].ffill(axis=1).iloc[:, [1, 3]]
)