I have the following data frame (say df1) in R:
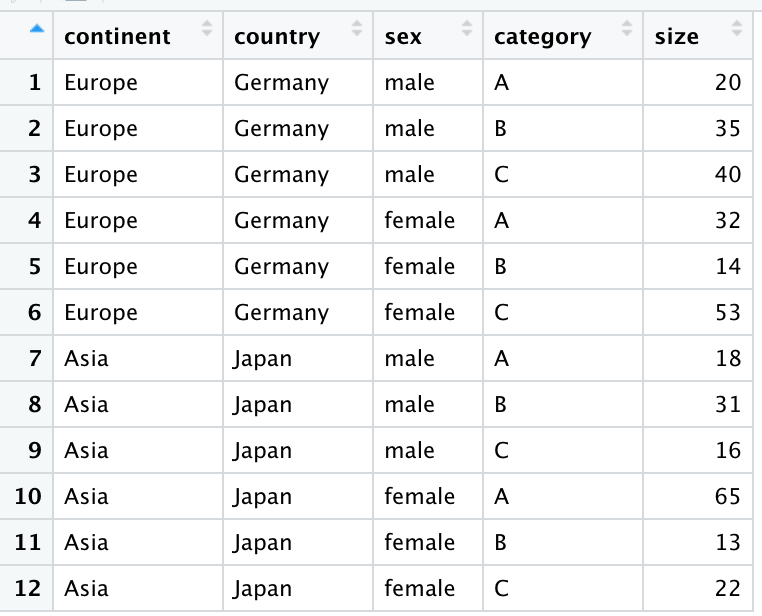
and would like to find the sum of the sizes for each of the "continent", "country", and "sex" combinations in cases where the category column values are A and B. I would then like to change the category value to D, and the desired new data frame (say df2) is given below:
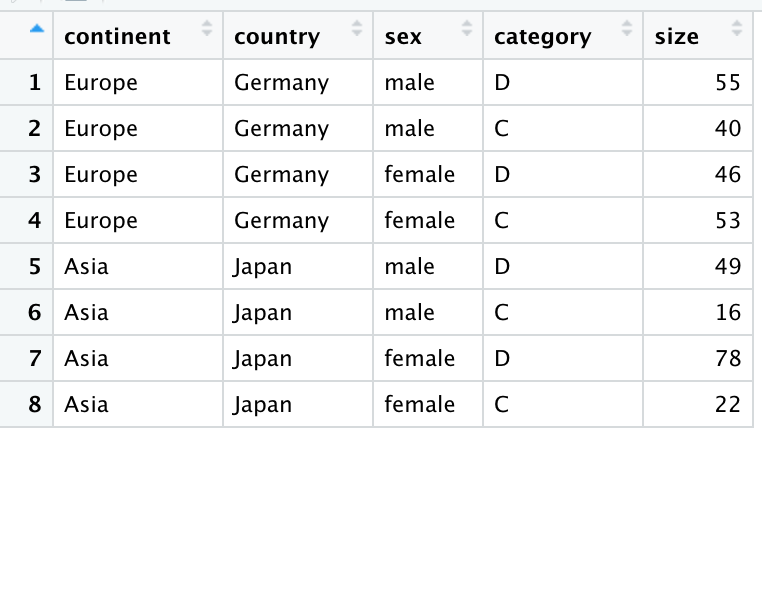
As I am new to R programming, I would really appreciate it if anyone can help me in converting the df1 to df2 and many thanks in advance.
PS. The code for my original data frame with category A, B, and C is given below:
df1 <- data.frame("continent" = c('Europe', 'Europe', 'Europe', 'Europe', 'Europe', 'Europe', 'Asia', 'Asia', 'Asia', 'Asia', 'Asia', 'Asia'),
"country" = c('Germany', 'Germany', 'Germany', 'Germany', 'Germany','Germany','Japan', 'Japan', 'Japan', 'Japan', 'Japan','Japan'),
"sex" = c('male', 'male', 'male', 'female', 'female', 'female', 'male', 'male', 'male', 'female', 'female', 'female'),
"category" = c('A', 'B', 'C','A', 'B', 'C', 'A', 'B', 'C', 'A', 'B', 'C'), "size" = c(20, 35, 40, 32, 14, 53,18,31, 16,65,13,22))
CodePudding user response:
It seems like the consecutiveness doesn't matter. You want to combine categories A and B into a new category D and then do a grouped sum:
df1 %>%
mutate(category = ifelse(category %in% c("A", "B"), "D", category)) %>%
group_by(continent, country, sex, category) %>%
summarize(size = sum(size), .groups = "drop")
# # A tibble: 8 × 5
# continent country sex category size
# <chr> <chr> <chr> <chr> <dbl>
# 1 Asia Japan female C 22
# 2 Asia Japan female D 78
# 3 Asia Japan male C 16
# 4 Asia Japan male D 49
# 5 Europe Germany female C 53
# 6 Europe Germany female D 46
# 7 Europe Germany male C 40
# 8 Europe Germany male D 55
CodePudding user response:
You can update column category and set it to D in case it is now A or B by using %in%. Then you can use aggregate to build the sum of the new group.
df1$category[df1$category %in% c("A", "B")] <- "D"
aggregate(size ~ ., df1, sum)
# continent country sex category size
#1 Europe Germany female C 53
#2 Asia Japan female C 22
#3 Europe Germany male C 40
#4 Asia Japan male C 16
#5 Europe Germany female D 46
#6 Asia Japan female D 78
#7 Europe Germany male D 55
#8 Asia Japan male D 49