Recently I've been trying to make some transformations in some Json files in the Azure Synapse notebooks using Scala language and loading them in using the spark.read function. The problem is the following one:
- 1st case: I load it using an schema (via Structype) and the returned DF is all null
- 2nd case: I load it withouth the schema and it returns "_corrupt_record" (this happens using multiline = true, too)
I do not know what is happening as I have tried to load different types of Jsons and none of them work (they are normal jsons downloaded from Kaggle, though).
{
"results": [{
"columns": [{
"name": "COD",
"type": "NUMBER"
}, {
"name": "TECH",
"type": "NUMBER"
}, {
"name": "OBJECT",
"type": "NUMBER"
}],
"items": [{
"cod": 3699,
"tech": "-",
"object": "Type 2"
}, {
"cod": 3700,
"tech": 56,
"object": "Type 1"
}, {
"cod": 3701,
"tech": 20,
"object": "No type"
}]
}]
}CodePudding user response:
I am getting similar kind of corrupt data error when I tried to reproduce
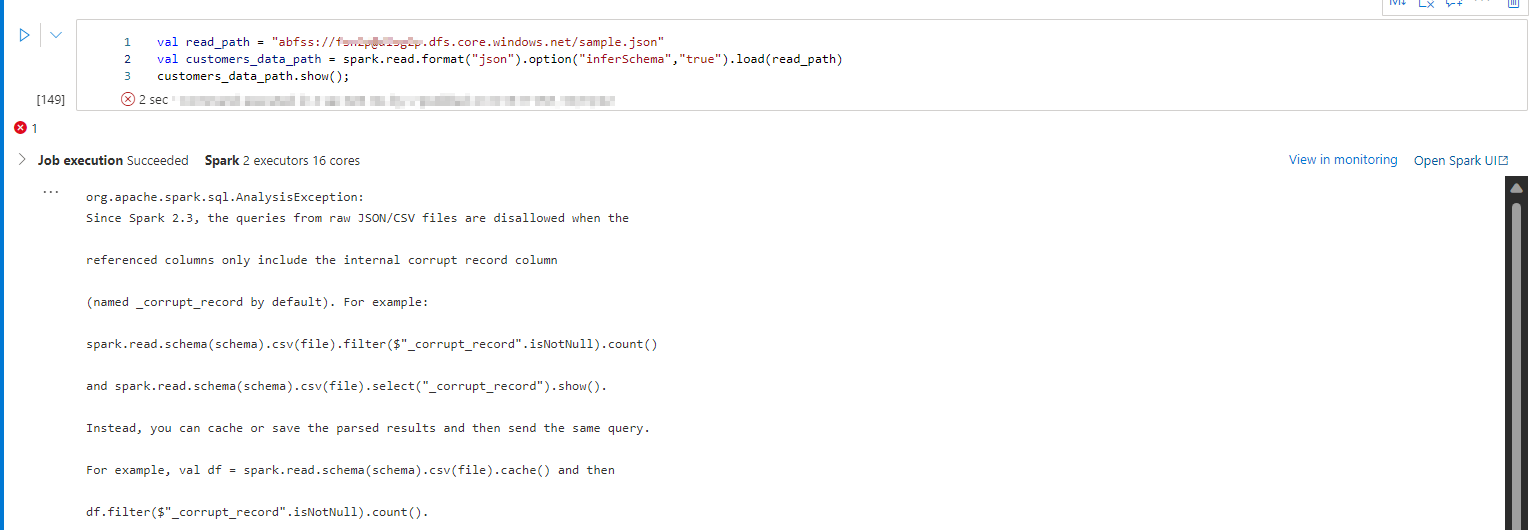
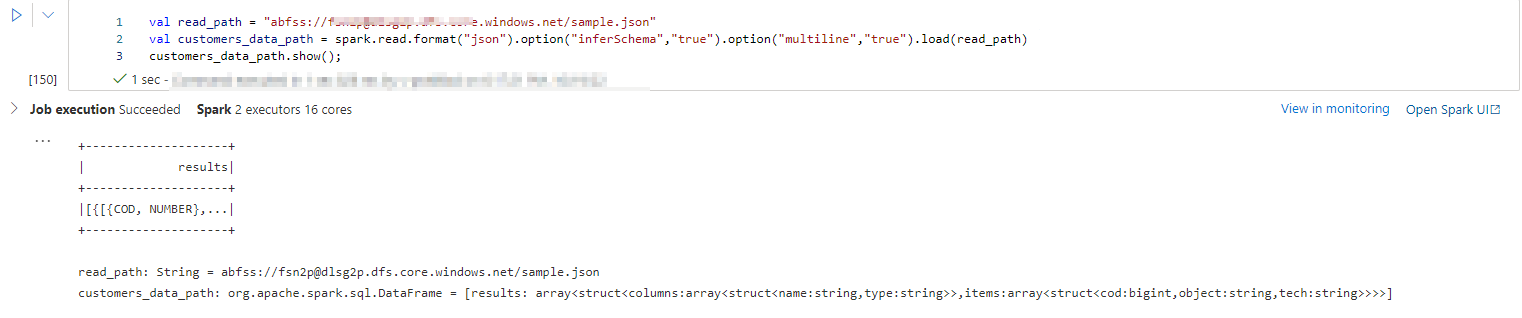
As you shared sample data it contains multiple lines to single object and the Json has multiple objects inside it to view this Json file, I used the multiline option as true and the exploded each column and selected it.
//reading JSON file from ADLS in json format
val read_path = "abfss://[email protected]/sample.json"
val customers_data_path = spark.read.format("json").option("inferSchema","true").option("multiline","true").load(read_path)
customers_data_path.show();
//Exploding the results column into its object as column
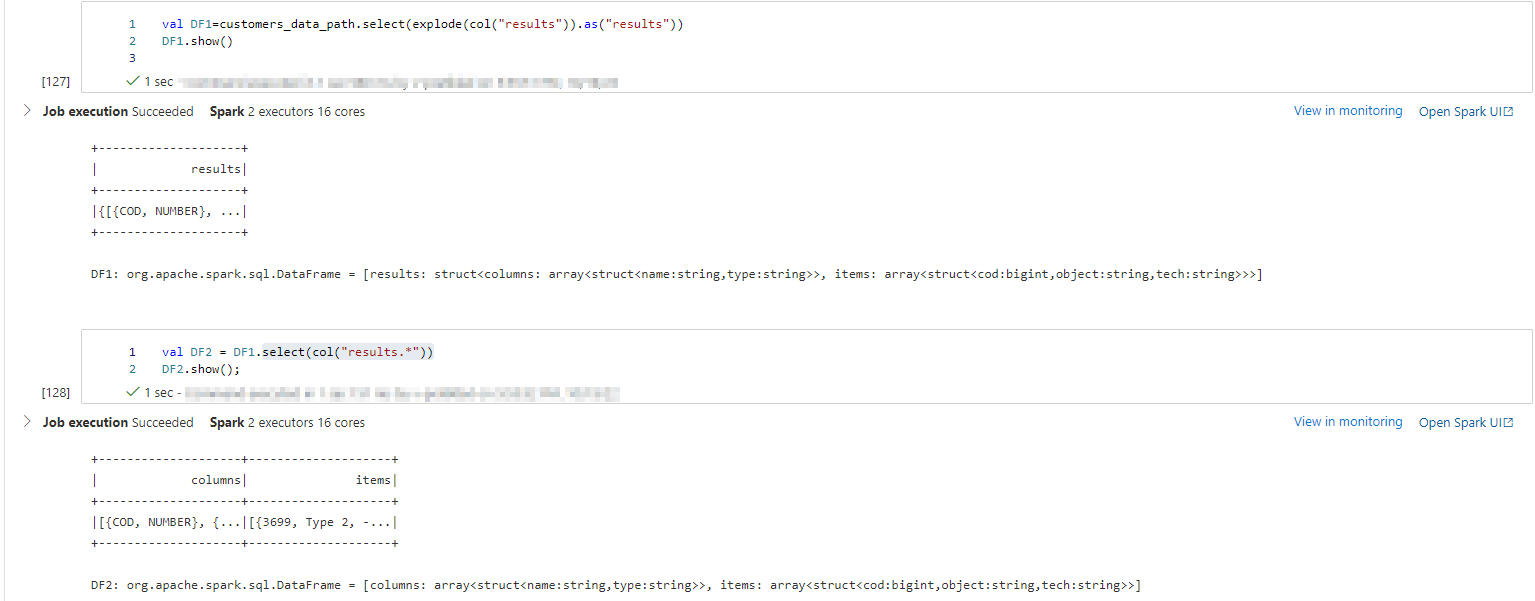
val DF1=customers_data_path.select(explode(col("results")).as("results"))
DF1.show()
//Selecting all columns from results
val DF2 = DF1.select(col("results.*"))
DF2.show();
//further exploding Columns column and items objects
val DF3 = DF2.select(explode(col("columns")).as("columns"),col("items"))
val DF4 = DF3.select(col("columns"),explode(col("items")).as("items"))
DF4.show();
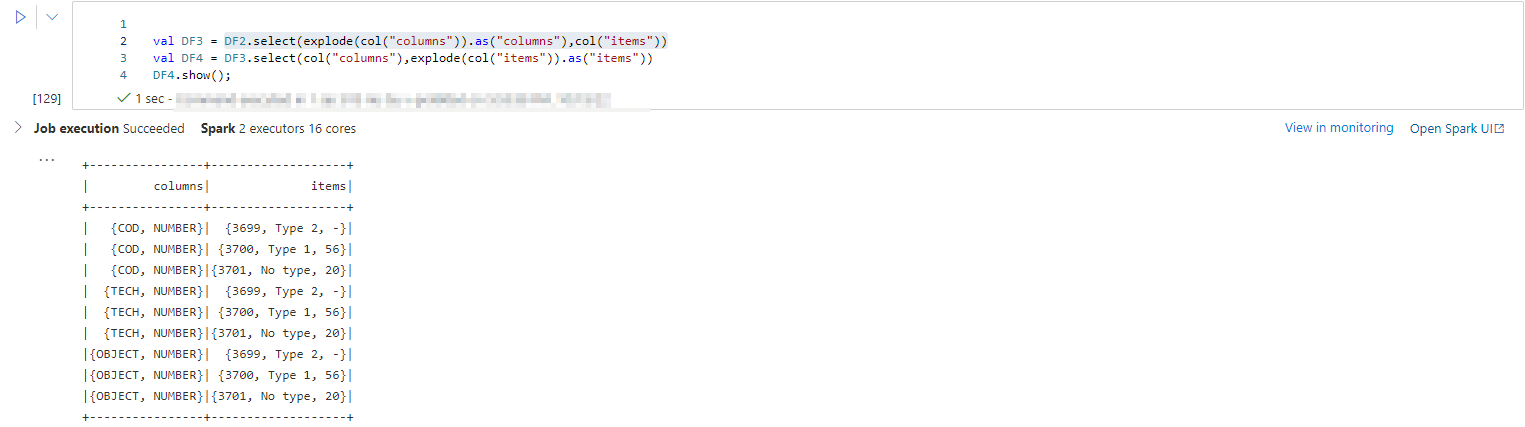
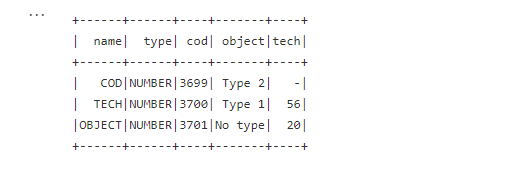
- In this approach you will each item object has all columns object value
//selecting All columns inside columns and items object
val DF5 = DF4.select(col("columns.*"),col("items.*"))
DF5.show();

- In this approach you will get null when object dont have value in particular colum.
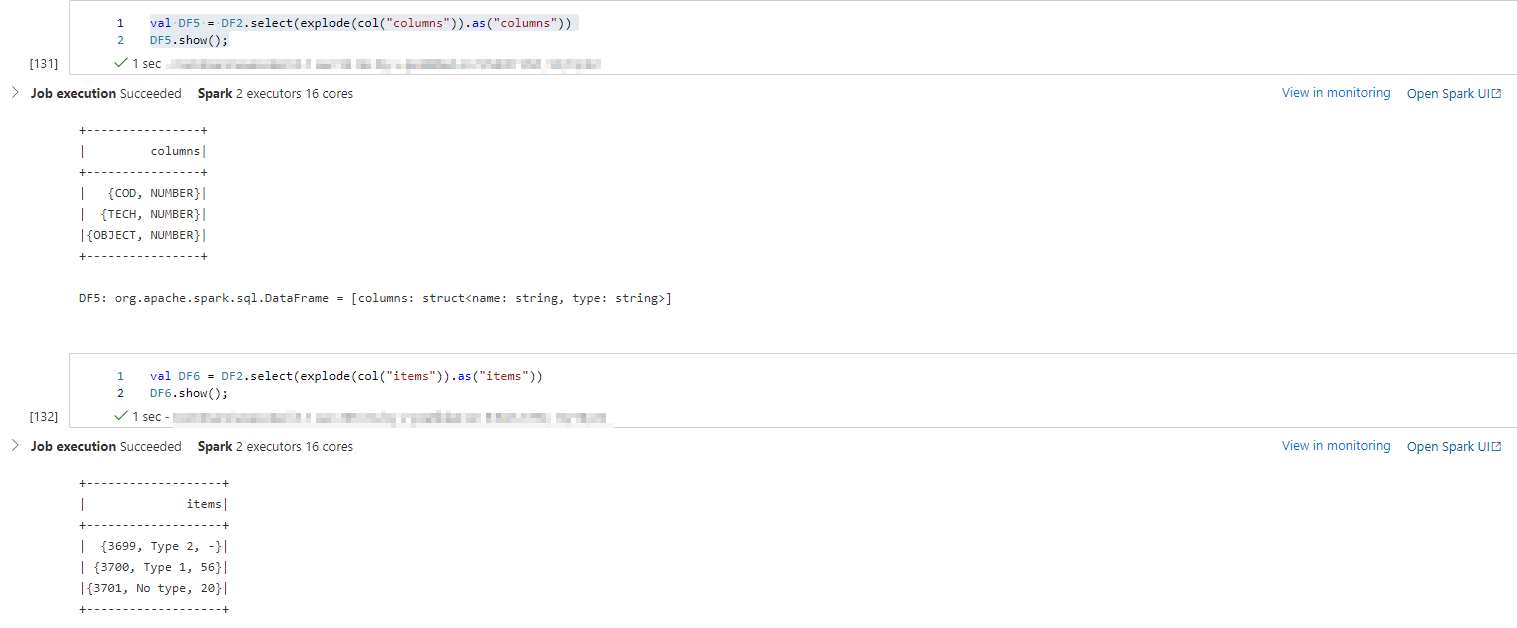
//exploding Columns column and items objects
val DF5 = DF2.select(explode(col("columns")).as("columns"))
DF5.show();
val DF6 = DF2.select(explode(col("items")).as("items"))
DF6.show();
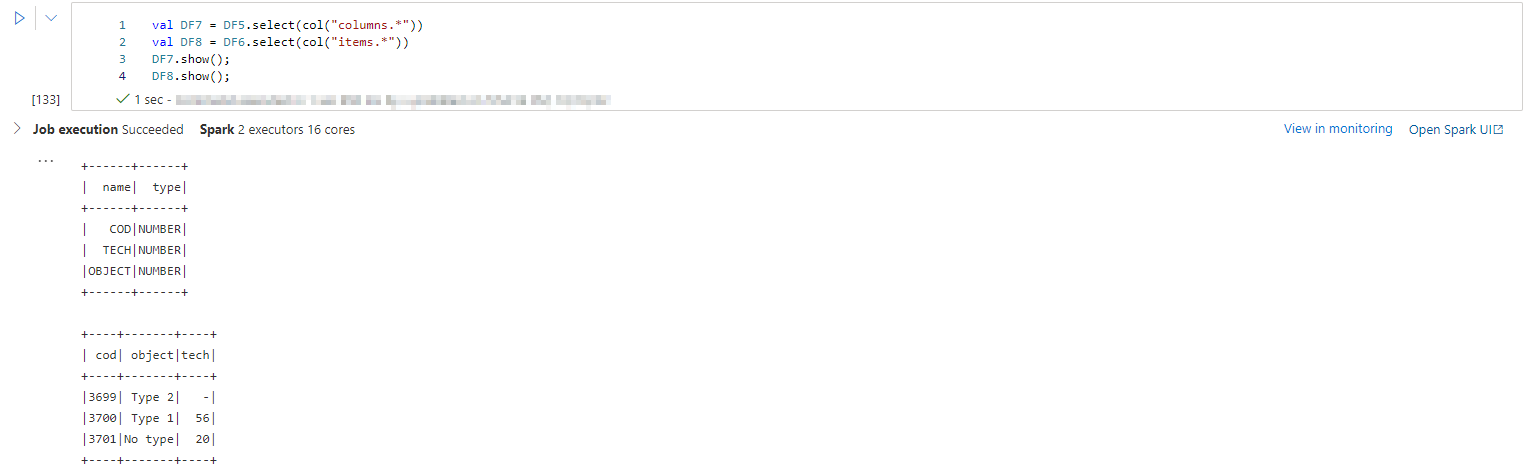
//selecting All columns inside columns and items object
val DF7 = DF5.select(col("columns.*"))
val DF8 = DF6.select(col("items.*"))
DF7.show();
DF8.show();
//combining both the above dataframes
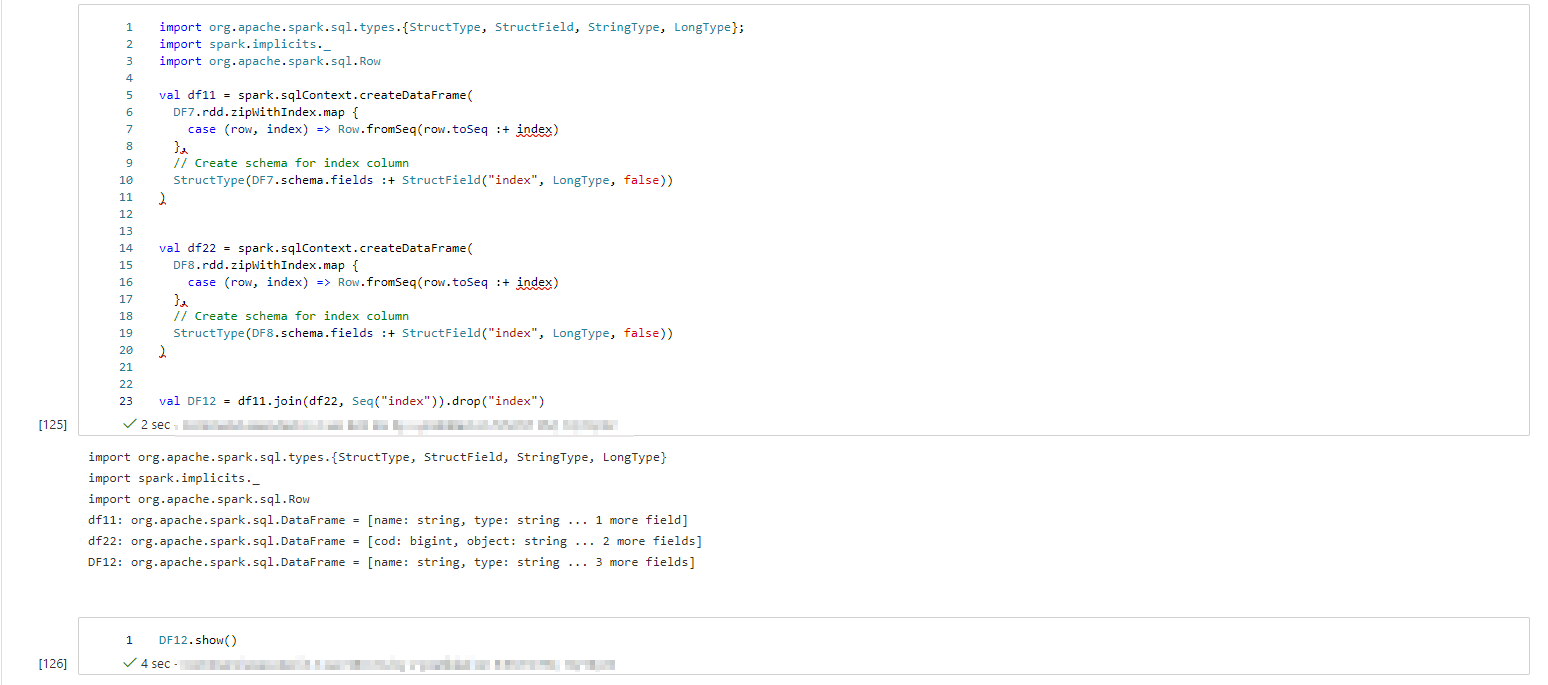
val DF10 = DF7.join(DF8, lit(false), "full").show()
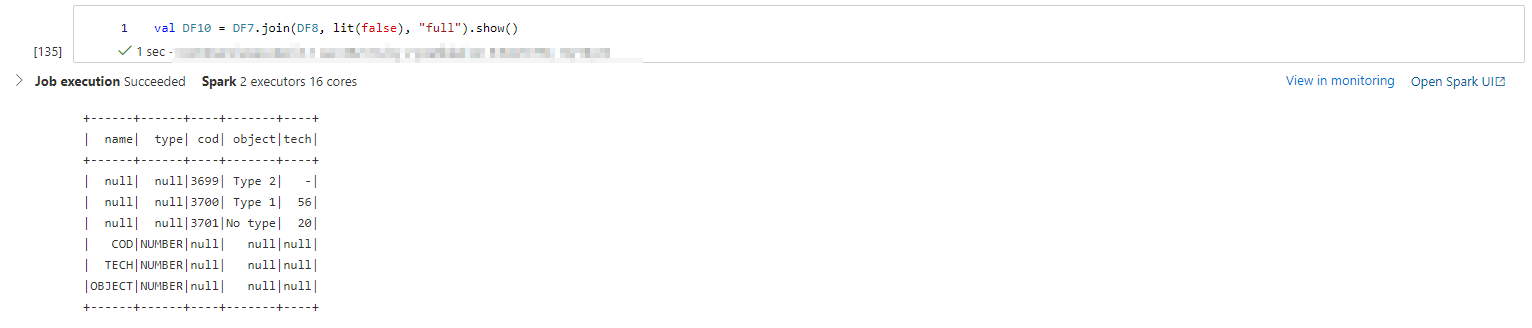
- In this approach you will get combined data frame for columns
//creating sequential index column with help of that join the data frames and then drop it.
import org.apache.spark.sql.types.{StructType, StructField, StringType, LongType};
import spark.implicits._
import org.apache.spark.sql.Row
val df11 = spark.sqlContext.createDataFrame(
DF7.rdd.zipWithIndex.map {
case (row, index) => Row.fromSeq(row.toSeq : index)
},
// Create schema for index column
StructType(DF7.schema.fields : StructField("index", LongType, false))
)
val df22 = spark.sqlContext.createDataFrame(
DF8.rdd.zipWithIndex.map {
case (row, index) => Row.fromSeq(row.toSeq : index)
},
// Create schema for index column
StructType(DF8.schema.fields : StructField("index", LongType, false))
)
val DF12 = df11.join(df22, Seq("index")).drop("index")
DF12.show()