Apologies in advance if this long question seems quite basic!
Given:
search query 
currently, I have the following code:
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
def run_selenium(URL):
options = Options()
options.add_argument("--remote-debugging-port=9222"),
options.headless = True
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
driver.get(URL)
pt = "//app-digiweb/ng-component/section/div/div/app-binding-search-results/div/div"
medias = driver.find_elements(By.XPATH, pt) # expect to obtain a list with 20 elements!!
print(medias) # >>>>>> result: []
print("#"*100)
for i, v in enumerate(medias):
print(i, v.get_attribute("innerHTML"))
if __name__ == '__main__':
url = 'https://digi.kansalliskirjasto.fi/search?query=economic crisis&orderBy=RELEVANCE'
run_selenium(URL=url)
Problem:
Having a look at part of the inspect in chrome:
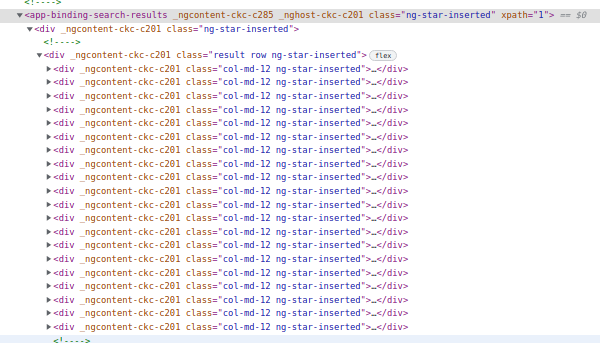
I have tried several xpath generated by Chrome Extensions XPath Helper and SelectorsHub to produce XPath and use it as pt variable in my python code this library search engine, but the result is [] or simply nothing.
Using SelectorsHub and hovering the mouse over Rel XPath, I get this warning: id & class both look dynamic. Uncheck id & class checkbox to generate rel xpath without them if it is generated with them.
Question:
Assuming selenium as a tool for web scraping with dynamic attributes instead of BeautifulSoup as recommended here and here, shouldn't driver.find_elements(), return a list of 20 elements each of which containing all info and to be extracted?
CodePudding user response:
This is an answer for Question#2 only since #1 and #3 (as Prophet've already said in comment) are not valid for SO.
Since you're dealing with dynamic content find_elements is not what you need. Try to wait for required data to appear:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
medias = WebDriverWait(driver, 10).until(EC.presence_of_all_elements_located((By.CLASS_NAME, 'media')))