I'm training a self-organizing map (SOM) using the kohonen library in R and I get some confusing results when I adjust the rlen parameter in the som call. According to the help file, rlen is the "the number of times the complete data set will be presented to the network," which seems straightforward enough. The confusing result happens when I view the convergence of the algorithm via plot(som_model, type="changes") for different values of rlen. This plot shows iterations vs. the average distance to a data vector, and from what I understand when we see it plateau we can assume the algorithm has converged. But as shown below, the number of iterations required for convergence seems to be a function of the number of iterations selected.
Using the built-in wines data set, I first plot the results with 300 iterations via:
som_model = som(scale(wines), grid = somgrid(6, 4, "hexagonal"), rlen = 300)
par(mar = c(5, 5, 1, 1))
plot(som_model, type="changes", main = "rlen=300")
As can be seen, the mean distance plateaus after ~200 iterations
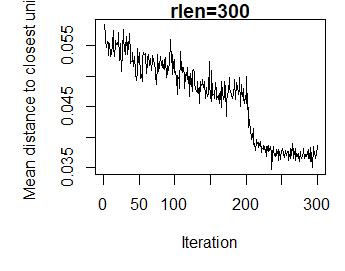
If I then then repeat this with rlen=1000, I get the following:
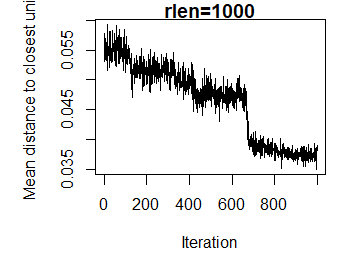
Now the mean distance plateaus at around 600 iterations. I suppose there is some consistency in that the plateau appears about 2/3 of the way through the number of iterations. But if I'm just changing how many times the data is presented to the SOM network, then why would things not converge at 200 iterations in both cases. I'm guessing I have a misunderstanding about what the algorithm is actually doing. Any help anyone can offer is greatly appreciated.
CodePudding user response:
From the vignette:
Several parameters of convergence force the adjustments to get smaller and smaller as training vectors are fed in many times, causing the map to stabilize into a representation.
The parameters are going to be adjusted for rlen--a larger rlen allows for smaller steps and presumably a more stable convergence. So, if a model is having a hard time converging, a larger value for rlen may be needed. And, obviously, if rlen is too small, it may not exhibit convergence (e.g., rlen = 60 on the wines dataset).
Another way to think about it--the weight of each training vector fed to the model is something like inversely proportional to rlen, so it takes more training vectors to achieve the same "movement" away from the initial vector with larger rlen values.