I'm currently trying to parse 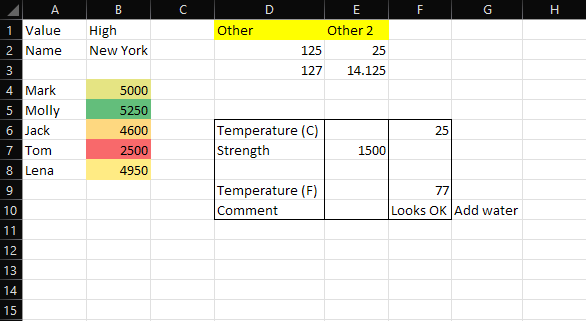
When I read in the excel using df_original = pd.read_excel(filename, sheet_name=sheet) the dataframe looks like this
df_original = pd.DataFrame({'Unnamed: 0':['Value', 'Name', np.nan, 'Mark', 'Molly', 'Jack', 'Tom', 'Lena', np.nan, np.nan],
'Unnamed: 1':['High', 'New York', np.nan, '5000', '5250', '4600', '2500', '4950', np.nan, np.nan],
'Unnamed: 2':[np.nan, np.nan, np.nan, np.nan, np.nan, np.nan, np.nan, np.nan, np.nan, np.nan],
'Unnamed: 3':['Other', 125, 127, np.nan, np.nan, 'Temperature (C)', 'Strength', np.nan, 'Temperature (F)', 'Comment'],
'Unnamed: 4':['Other 2', 25, 14.125, np.nan, np.nan, np.nan, '1500', np.nan, np.nan, np.nan],
'Unnamed: 5':[np.nan, np.nan, np.nan, np.nan, np.nan, 25, np.nan, np.nan, 77, 'Looks OK'],
'Unnamed: 6':[np.nan, np.nan, np.nan, np.nan, np.nan, np.nan, np.nan, np.nan, np.nan, 'Add water'],
})
---- -------------- -------------- -------------- ----------------- -------------- -------------- --------------
| | Unnamed: 0 | Unnamed: 1 | Unnamed: 2 | Unnamed: 3 | Unnamed: 4 | Unnamed: 5 | Unnamed: 6 |
|---- -------------- -------------- -------------- ----------------- -------------- -------------- --------------|
| 0 | Value | High | nan | Other | Other 2 | nan | nan |
| 1 | Name | New York | nan | 125 | 25 | nan | nan |
| 2 | nan | nan | nan | 127 | 14.125 | nan | nan |
| 3 | Mark | 5000 | nan | nan | nan | nan | nan |
| 4 | Molly | 5250 | nan | nan | nan | nan | nan |
| 5 | Jack | 4600 | nan | Temperature (C) | nan | 25 | nan |
| 6 | Tom | 2500 | nan | Strength | 1500 | nan | nan |
| 7 | Lena | 4950 | nan | nan | nan | nan | nan |
| 8 | nan | nan | nan | Temperature (F) | nan | 77 | nan |
| 9 | nan | nan | nan | Comment | nan | Looks OK | Add water |
---- -------------- -------------- -------------- ----------------- -------------- -------------- --------------
This code finds the rows of interest and solves Goal 1.
df = df_original.dropna(how='all', axis=1)
pattern = r'[Tt]emperature|[Ss]tren|[Cc]omment'
mask = np.column_stack([df[col].str.contains(pattern, regex=True, na=False) for col in df])
row_range = df.loc[(mask.any(axis=1))].index.to_list()
print(df.loc[(mask.any(axis=1))].index.to_list())
[5, 6, 8, 9]
display(df.loc[row_range])
---- -------------- -------------- ----------------- -------------- -------------- --------------
| | Unnamed: 0 | Unnamed: 1 | Unnamed: 3 | Unnamed: 4 | Unnamed: 5 | Unnamed: 6 |
|---- -------------- -------------- ----------------- -------------- -------------- --------------|
| 5 | Jack | 4600 | Temperature (C) | nan | 25 | nan |
| 6 | Tom | 2500 | Strength | 1500 | nan | nan |
| 8 | nan | nan | Temperature (F) | nan | 77 | nan |
| 9 | nan | nan | Comment | nan | Looks OK | Add water |
---- -------------- -------------- ----------------- -------------- -------------- --------------
What is the easiest way to solve Goal 2? Basically I want to find columns that contain at least one value that matches the regex pattern. The wanted output would be [Unnamed: 5]. There may be some easy way to solve goals 1 and 2 at the same time. For example:
col_of_interest = 'Unnamed: 3' # <- find this value
col_range = df_original.columns[df_original.columns.to_list().index(col_of_interest): ]
print(col_range)
Index(['Unnamed: 3', 'Unnamed: 4', 'Unnamed: 5', 'Unnamed: 6'], dtype='object')
target = df_original.loc[row_range, col_range]
display(target)
---- ----------------- -------------- -------------- --------------
| | Unnamed: 3 | Unnamed: 4 | Unnamed: 5 | Unnamed: 6 |
|---- ----------------- -------------- -------------- --------------|
| 5 | Temperature (C) | nan | 25 | nan |
| 6 | Strength | 1500 | nan | nan |
| 8 | Temperature (F) | nan | 77 | nan |
| 9 | Comment | nan | Looks OK | Add water |
---- ----------------- -------------- -------------- --------------
CodePudding user response:
One option is with xlsx_cells from pyjanitor; it reads each cell as a single row; this way you are afforded more manipulation freedom; for your use case it can be handy and an alternative:
# pip install pyjanitor
import pandas as pd
import janitor as jn
Read in data
df = jn.xlsx_cells('test.xlsx', include_blank_cells=False)
df.head()
value internal_value coordinate row column data_type is_date number_format
0 Value Value A2 2 1 s False General
1 High High B2 2 2 s False General
2 Other Other D2 2 4 s False General
3 Other 2 Other 2 E2 2 5 s False General
4 Name Name A3 3 1 s False General
Filter for rows that match the pattern:
bools = df.value.str.startswith(('Temperature', 'Strength', 'Comment'), na = False)
vals = df.loc[bools, ['value', 'row', 'column']]
vals
value row column
16 Temperature (C) 7 4
20 Strength 8 4
24 Temperature (F) 10 4
26 Comment 11 4
Look for values that are on the same row as vals, and are in columns greater than the column in vals:
bools = df.column.gt(vals.column.unique().item()) & df.row.between(vals.row.min(), vals.row.max())
result = df.loc[bools, ['value', 'row', 'column']]
result
value row column
17 25 7 6
21 1500 8 5
25 77 10 6
27 Looks OK 11 6
28 Add water 11 7
Merge vals and result to get the final output
(vals
.drop(columns='column')
.rename(columns={'value':'val'})
.merge(result.drop(columns='column'))
)
val row value
0 Temperature (C) 7 25
1 Strength 8 1500
2 Temperature (F) 10 77
3 Comment 11 Looks OK
4 Comment 11 Add water
CodePudding user response:
Try one of the following 2 options:
Option 1 (assuming no not-NaN data below row with "[Tt]emperature (C)" that we don't want to include)
pattern = r'[Tt]emperature'
idx, col = df_original.stack().str.contains(pattern, regex=True, na=False).idxmax()
res = df_original.loc[idx:, col:].dropna(how='all')
print(res)
Unnamed: 3 Unnamed: 4 Unnamed: 5 Unnamed: 6
5 Temperature (C) NaN 25 NaN
6 Strength 1500 NaN NaN
8 Temperature (F) NaN 77 NaN
9 Comment NaN Looks OK Add water
Explanation
- First, we use
df.stackto add column names as a level to the index, and get all the data just in one column. - Now, we can apply
Series.str.containsto find a match forr'[Tt]emperature'. We chainSeries.idxmaxto "[r]eturn the row label of the maximum value". I.e. this will be the firstTrue, so we will get back(5, 'Unnamed: 3'), to be stored inidxandcolrespectively. - Now, we know where to start our selection from the
df, namely at index5and columnUnnamed: 3. If we simply want all the data (to the right, and to bottom) from here on, we can use:df_original.loc[idx:, col:]and finally, drop all remaining rows that have onlyNaNvalues.
Option 2 (potential data below row with "[Tt]emperature (C)" that we don't want to include)
pattern = r'[Tt]emperature|[Ss]tren|[Cc]omment'
tmp = df_original.stack().str.contains(pattern, regex=True, na=False)
tmp = tmp[tmp].index
res = df_original.loc[tmp.get_level_values(0), tmp.get_level_values(1)[1]:]
print(res)
Unnamed: 3 Unnamed: 4 Unnamed: 5 Unnamed: 6
5 Temperature (C) NaN 25 NaN
6 Strength 1500 NaN NaN
8 Temperature (F) NaN 77 NaN
9 Comment NaN Looks OK Add water
Explanantion
- Basically, the procedure here is the same as with option 1, except that we want to retrieve all the
index values, rather than just the first one (for "[Tt]emperature (C)"). Aftertmp[tmp].index, we gettmpas:
MultiIndex([(5, 'Unnamed: 3'),
(6, 'Unnamed: 3'),
(8, 'Unnamed: 3'),
(9, 'Unnamed: 3')],
)
- In the next step, we use these values as coordinates for
df.loc. I.e. for the index selection, we want all values, so we useindex.get_level_values; for the column, we only need the first value (they should all be the same of course:Unnamed: 3).