I'm trying to recreate the output of loading an SPSS sav file using haven, which has attributes attached to each column, like so:
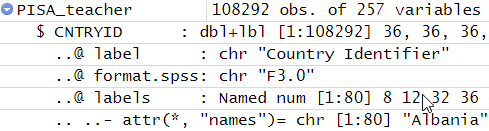
> class(PISA_teacher)
[1] "tbl_df" "tbl" "data.frame"
My code is as so:
df <- list(c(1,2,3,4), c("c","d","e","a")) %>% as.data.frame()
names(df) <- c("CNTRYID","Grade")
attr(df$CNTRYID, "label") <- c("Country Identifier")
But it gives me a different sort of attribute, one without an @:

How can I get something similar to the SPSS sav output?
The dput of the PISA_teacher dataframe is as follows:
structure(list(CNTRYID = structure(c(36, 36, 36), label = "Country Identifier", format.spss = "F3.0", labels = c(Albania = 8, Algeria = 12, Argentina = 32, Australia = 36, Austria = 40, Belgium = 56, Brazil = 76, Bulgaria = 100, Canada = 124, Chile = 152, `Chinese Taipei` = 158, Colombia = 170, `Costa Rica` = 188, Croatia = 191, Cyprus = 196, `Czech Republic` = 203, Denmark = 208, `Dominican Republic` = 214, Estonia = 233, Finland = 246, France = 250, Georgia = 268, Germany = 276, Greece = 300, `Hong Kong` = 344, Hungary = 348, Iceland = 352, Indonesia = 360, Ireland = 372, Israel = 376, Italy = 380, Japan = 392, Kazakhstan = 398, Jordan = 400, Korea = 410, Kosovo = 411, Lebanon = 422, Latvia = 428, Lithuania = 440, Luxembourg = 442, Macao = 446, Malaysia = 458, Malta = 470, Mexico = 484, Moldova = 498, Montenegro = 499, Netherlands = 528, `New Zealand` = 554, Norway = 578, Peru = 604, Poland = 616, Portugal = 620, `Puerto Rico (USA)` = 630, Qatar = 634, Romania = 642, `Russian Federation` = 643, Singapore = 702, `Slovak Republic` = 703, Vietnam = 704, Slovenia = 705, Spain = 724, `Spain (Regions)` = 725, Sweden = 752, Switzerland = 756, Thailand = 764, `Trinidad and Tobago` = 780, `United Arab Emirates` = 784, Tunisia = 788, Turkey = 792, FYROM = 807, `United Kingdom` = 826, `United Kingdom - excl. Scotland` = 827, Scotland = 828, `United States` = 840, Uruguay = 858, `B-S-J-G (China)` = 970, `Spain (Regions)` = 971, `USA (Massachusetts)` = 972, `USA (North Carolina)` = 973, `Argentina (Ciudad Autónoma de Buenos)` = 974), class = c("haven_labelled", "vctrs_vctr", "double")), CNT = structure(c("AUS", "AUS", "AUS"), label = "Country code 3-character", format.spss = "A3", display_width = 3L, labels = c(Moldova = "MDA", Thailand = "THA", Brazil = "BRA", France = "FRA", `United States` = "USA", Italy = "ITA", Latvia = "LVA", Algeria = "DZA", Albania = "ALB", Macao = "MAC", Greece = "GRC", Scotland = "QSC", `Massachusettes (USA)` = "QUC", FYROM = "MKD", Netherlands = "NLD", `Puerto Rico (USA)` = "QUD", Switzerland = "CHE", Montenegro = "MNE", `United Arab Emirates` = "ARE", `North Carolina (USA)` = "QUE", Sweden = "SWE", `Czech Republic` = "CZE", `Hong Kong` = "HKG", Argentina = "ARG", `B-S-J-G (China)` = "QCH", `Costa Rica` = "CRI", Denmark = "DNK", `United Kingdom - excl. Scotland` = "QUK", `Slovak Republic` = "SVK", Belgium = "BEL", `Belgium (Flemish)` = "BFL", Chile = "CHL", Colombia = "COL", Poland = "POL", Ireland = "IRL", Iceland = "ISL", `New Zealand` = "NZL", Vietnam = "VNM", `Dominican Republic` = "DOM", Canada = "CAN", Lebanon = "LBN", Indonesia = "IDN", China = "CHN", Finland = "FIN", Japan = "JPN", Hungary = "HUN", Tunisia = "TUN", Slovenia = "SVN", Georgia = "GEO", `Trinidad and Tobago` = "TTO", `Chinese Taipei` = "TAP", Singapore = "SGP", Spain = "ESP", `Argentina (Ciudad Autónoma de Buenos)` = "QAR", `United Kingdom` = "GBR", Peru = "PER", `Belgium (French)` = "BFR", Bulgaria = "BGR", Jordan = "JOR", Korea = "KOR", Norway = "NOR", Israel = "ISR", Turkey = "TUR", `Spain (Regions)` = "QES", Australia = "AUS", `Russian Federation` = "RUS", Malaysia = "MYS", Qatar = "QAT", Malta = "MLT", Portugal = "PRT", Estonia = "EST", Austria = "AUT", Germany = "DEU", Romania = "ROU", Lithuania = "LTU", Croatia = "HRV", Kosovo = "KSV", Mexico = "MEX", Luxembourg = "LUX", Cyprus = "QCY", Uruguay = "URY", Kazakhstan = "KAZ", `International Master` = "ZZZ"), class = c("haven_labelled", "vctrs_vctr", "character"))), row.names = c(NA, -3L), class = c("tbl_df", "tbl", "data.frame"))
CodePudding user response:
Use haven::labelled (this doesn't get you the @format.spss component, but it gets you everything else)
library(dplyr)
library(haven)
df <- data.frame(CNTRYID = c(1,2,3,4), Grade = c("c","d","e","a"))
df |>
mutate(across(CNTRYID, labelled,
labels = c("Albania"=1, "Austria"=2, "Zambia"=3, "Zimbabwe"=4),
label = "Country Name"))
The documentation does say
I expect you'll coerce to a standard R class (e.g. a ‘factor()’) soon after importing.