I'm working with data that looks like this:
id <- c("673506", "624401", "674764")
bills <- c("sb 1181; ab 573; ab 2697",
"sb 1181; ab 573; ab 2697; ab 2448",
"sb 292; ab 497")
df <- data.frame(id, bills)
df
How can I transform the data so that the data is long from, the IDs repeat per every corresponding bill separated by a semi-colon?
Such that the data looks like this:
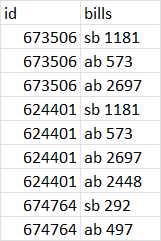
Thank you!
CodePudding user response:
Use separate_rows
library(tidyr)
separate_rows(df, bills, sep = ";\\s ")
-output
# A tibble: 9 × 2
id bills
<chr> <chr>
1 673506 sb 1181
2 673506 ab 573
3 673506 ab 2697
4 624401 sb 1181
5 624401 ab 573
6 624401 ab 2697
7 624401 ab 2448
8 674764 sb 292
9 674764 ab 497
CodePudding user response:
Base R approach.
do.call(rbind, c(Map(cbind, df$id, strsplit(df$bills, '; ')))) |>
as.data.frame() |> setNames(names(df))
# id bills
# 1 673506 sb 1181
# 2 673506 ab 573
# 3 673506 ab 2697
# 4 624401 sb 1181
# 5 624401 ab 573
# 6 624401 ab 2697
# 7 624401 ab 2448
# 8 674764 sb 292
# 9 674764 ab 497