I am doing a image segmentation using resnet50 as encoder and made the decoder with unpooling layers with skip layers in tensorflow
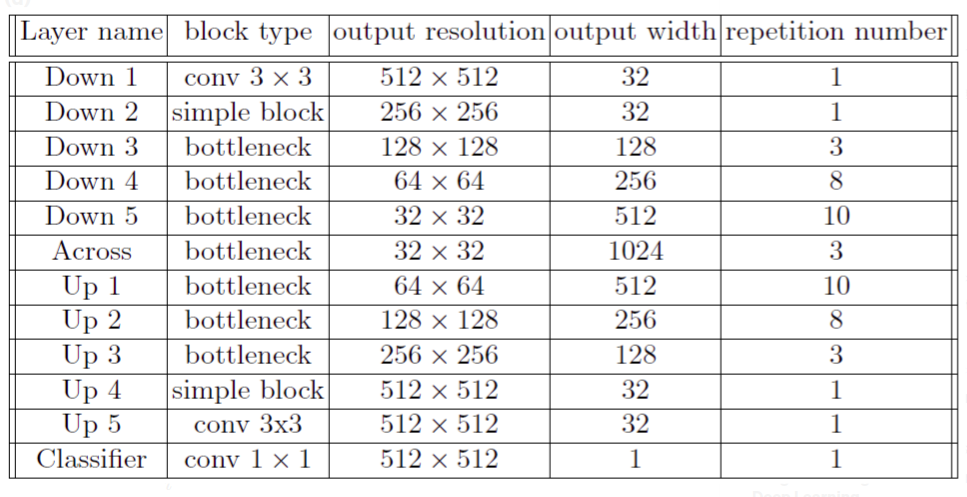
Here is the model structure,
For the loss function, I used the dice_coefficient and IOU formula, and calculated the total loss by adding both. In addition to the total loss, I added the REGULARIZATION_LOSSES from the network
total_loss = tf.add_n([dice_coefficient_output IOU_output] tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES))
Training started, In the 1st epoch, the total loss will be around 0.4
But, in the 2nd epoch, the total loss is shown as nan it
After decoding the loss values, the tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES) have the list of values for each layer, there, in most of the layers returns nan.
For this challenge, I tried using different normalisation like scale image data to = 0 to 1, -1 to 1, z-score, but the nan appears in the 2nd epoch.
I tried to reduce the learning rate, changed the weight decay in the l2 regularization, but the nan stays same from 2nd epoch.
Finally, I reduced the neurons in the network, and started the training, the nan disappeared in the 2nd epoch but appeared in the 4th epoch.
Any suggestion to improve this model, how to get rid of the nan in the regularization_loss
Thanks
CodePudding user response:
Two possible solutions:
- You may have an issue with the input data. Try calling assert not np.any(np.isnan(x)) on the input data to make sure you are not introducing the nan. Also make sure all of the target values are valid. Finally, make sure the data is properly normalized. You probably want to have the pixels in the range [-1, 1] and not [0, 255], example:
tf.keras.utils.normalize(data)
Other related options to the above would be that usually, the gradients become NaN first. The first two things to look at are a reduced learning rate and possibly gradient clipping.
Alternatively, you can try dividing by some constant first (perhaps equal to the max value of your data?) The idea is to get the values low enough that they don’t cause really large gradients.
- The labels must be in the domain of the loss function, so if using a logarithmic-based loss function all labels must be non-negative.
Otherwise see this link: https://discuss.pytorch.org/t/getting-nan-after-first-iteration-with-custom-loss/25929/7
Understanding domain adapation for labels that must be within the domain of the loss function: