page normally loads like this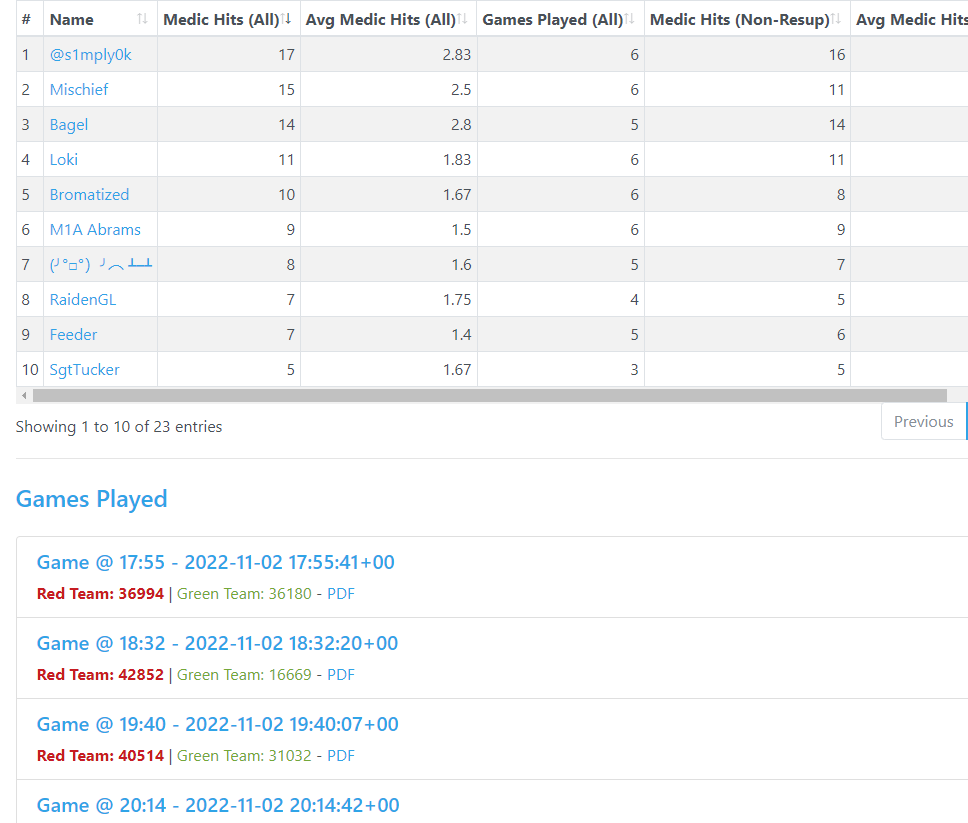
but when it is open with chrome driver via the selenium in python it loads like this
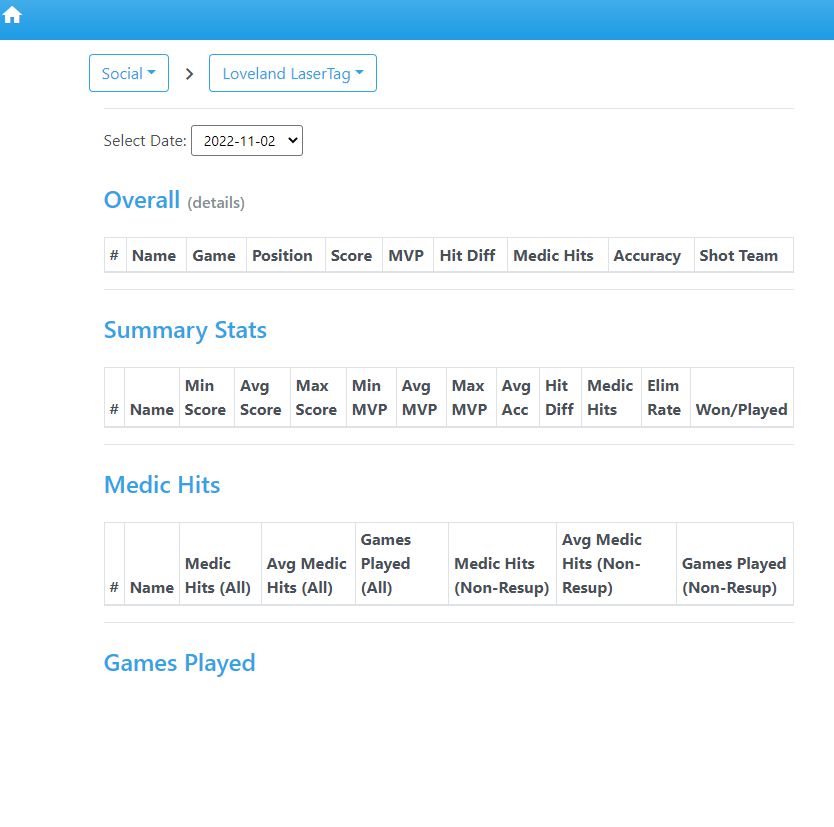
I have looked up how to start js scripts on a page, rocket-loader.min.js is a consistent thing I see in the pages source, but nothing I try works (javascriptexecutor, implicite wait, explicit wait, time.sleep()) nothing seems to get the page to load so I can scrape the results from it. her is my code for reference
date = ["2022-11-02","2022-10-26","2022-10-19","2022-10-05"]
html = []
url = 'https://lfstats.com/scorecards/nightly?gametype=social¢erID=10&leagueID=0&isComp=0&date='
for x in date:
driver = webdriver.Chrome('C:\\Program Files\\Google\\Chrome\\Application\\chromedriver.exe')
driver.get(url str(date))
time.sleep(10)
lnks = driver.find_element(By.XPATH, '/html/body/div[2]/div/div[2]/ul/div[1]/div[1]/a')
print(lnks)
try:
for link in lnks:
get = link.find_element(By.CSS_SELECTOR, 'a')
hyper = (get.get_attribute('href'))
html.append(hyper)
except:
print("unable to find link in group")
any help would be greatly appreciated. I am moderately good at python but new to web scraping and html code. please feel free to comment with how big of an idiot I am. thank you.
CodePudding user response:
This is not related to the javascript enabled or disabled issue. The actual issue is you are not passing the date from the 'date' list to the url correctly.
In the for loop, you have to make the below change:
for x in range(len(date)): # you have to loop through the length of the 'date' list
driver = webdriver.Chrome('C:\\Program Files\\Google\\Chrome\\Application\\chromedriver.exe')
driver.get(url str(date[x]))
time.sleep(10)
# in the below line you have to use find_elements, also I updated the correct locator
lnks = driver.find_elements(By.XPATH, ".//*[@class='list-group-item-heading']")
try:
for link in lnks:
get = link.find_element(By.CSS_SELECTOR, 'a')
hyper = (get.get_attribute('href'))
html.append(hyper)
except:
print("unable to find link in group")