I have created this pandas dataframe:
import numpy as np
import pandas as pd
ds = {"col1":[1,2,3,2,2,2,3,4,1,0,0,0,0,0,1,2,3,5]}
df = pd.DataFrame(data=ds)
which looks like this:
print(df)
col1
0 1
1 2
2 3
3 2
4 2
5 2
6 3
7 4
8 1
9 0
10 0
11 0
12 0
13 0
14 1
15 2
16 3
17 5
I need to create a new column (col2) which contains the cumulative count of the values in col1. So, the resulting dataframe would look like this:
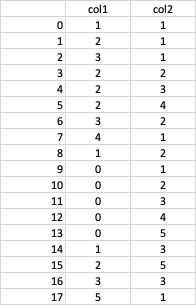
Does anybody know how to do it, please?
CodePudding user response:
There is precisely a grouby.cumcount function:
df['col2'] = df.groupby('col1').cumcount().add(1)
Output:
col1 col2
0 1 1
1 2 1
2 3 1
3 2 2
4 2 3
5 2 4
6 3 2
7 4 1
8 1 2
9 0 1
10 0 2
11 0 3
12 0 4
13 0 5
14 1 3
15 2 5
16 3 3
17 5 1
CodePudding user response:
Consider using cumcount() after groupby(). Add 1 to start counting from 1 instead of 0:
df['col2'] = df.groupby('col1').cumcount() 1
Returns:
col1 col2
0 1 1
1 2 1
2 3 1
3 2 2
4 2 3
5 2 4
6 3 2
7 4 1
8 1 2
9 0 1
10 0 2
11 0 3
12 0 4
13 0 5
14 1 3
15 2 5
16 3 3
17 5 1