I want to have a graph with a color scale, however the graph has certain deviations, where the first category is missing and then the color scale does not work any more. Is there a method to skip the first discrete color in a color scale?
I provide an example that does not work below. The first graph has category A in light blue, and the second B. But also in the second B should be dark blue.
I also found this question: 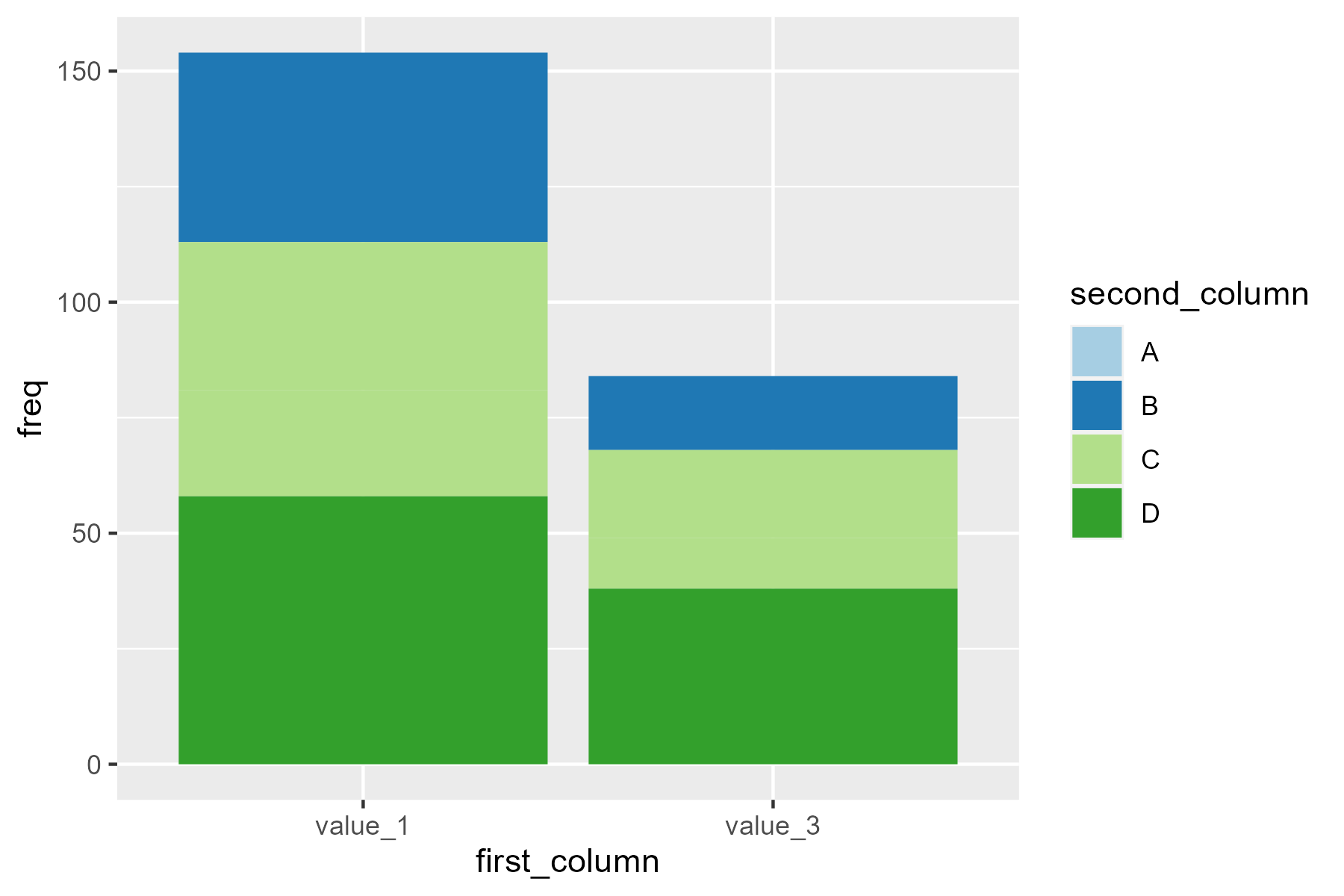
Edited example data:
first_column <- c(rep(c("value_1", "value_3"), each = 4))
second_column <- c("A", "B", "C", "D", "A", "B", "C", "D")
freq <- c(23, 41, 32, 58, 11, 16, 19, 38)
df2 <- data.frame(first_column, second_column, freq)
CodePudding user response:
One option would be to switch to scale_fill_manual and use a named vector to assign colors to categories.
library(ggplot2)
pal_fill <- scales::brewer_pal(palette = "Paired")(4)
names(pal_fill) <- LETTERS[1:4]
pal_fill
#> A B C D
#> "#A6CEE3" "#1F78B4" "#B2DF8A" "#33A02C"
ggplot(
df3,
aes(
x = first_column,
y = freq,
fill = second_column
)
)
geom_bar(stat = "identity")
scale_fill_manual(values = pal_fill)
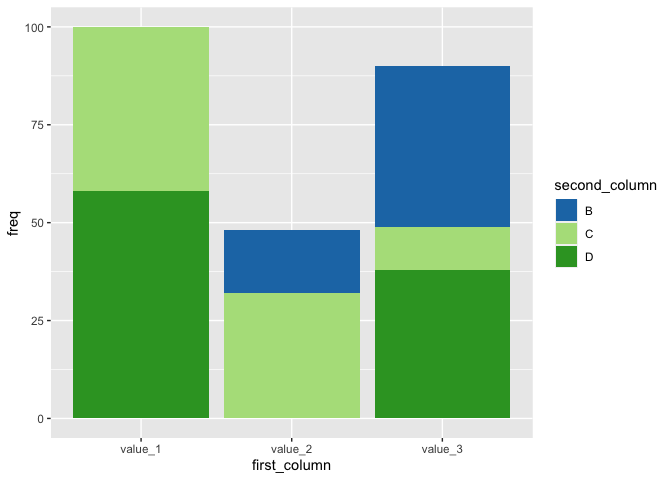
DATA
df3 <- structure(list(first_column = c("value_1", "value_3", "value_2",
"value_1", "value_3", "value_2", "value_1", "value_3"), second_column = c("C",
"B", "C", "D", "C", "B", "C", "D"), freq = c(23, 41, 32, 58,
11, 16, 19, 38)), row.names = c(NA, -8L), class = "data.frame")