I have a dataframe, df, with datetimeindex and a single column, like this:
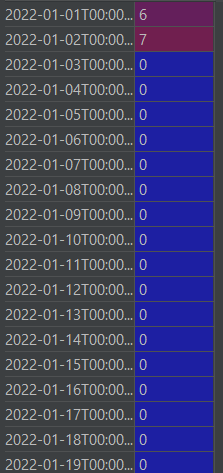
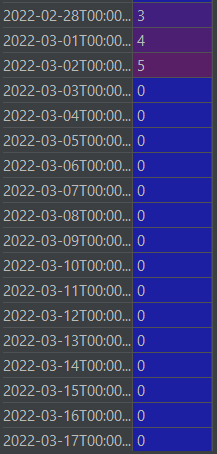
I need to count how many non-zero entries i have at each month. For example, according to those images, in January i would have 2 entries, in February 1 entry and in March 2 entries. I have more months in the dataframe, but i guess that explains the problem.
I tried using pandas groupby:
df.groupby(df.index.month).count()
But that just gives me total days at each month and i don't saw any other parameter in count() that i could use here.
Any ideas?
CodePudding user response:
For example:
In [1]: import pandas as pd
import numpy as np
x_df = pd.DataFrame(
{
'values': np.random.randint(low=0, high=2, size=(120,))
} ,
index = pd.date_range("2022-01-01", periods=120, freq="D")
)
In [2]: x_df
Out[2]:
values
2022-01-01 0
2022-01-02 0
2022-01-03 1
2022-01-04 0
2022-01-05 0
...
2022-04-26 1
2022-04-27 0
2022-04-28 0
2022-04-29 1
2022-04-30 1
[120 rows x 1 columns]
In [3]: x_df[x_df['values'] != 0].groupby(lambda x: x.to_period("M")).count()
Out[3]:
values
2022-01 17
2022-02 15
2022-03 16
2022-04 17
CodePudding user response:
can you try this:
#drop nans
import numpy as np
dfx['col1']=dfx['col1'].replace(0,np.nan)
dfx=dfx.dropna()
dfx=dfx.resample('1M').count()