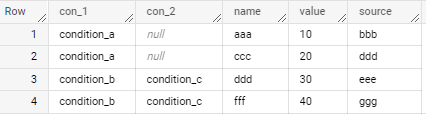
I have a JSON that looks something like that one:
{
"condition_a":{
"name": "aaa",
"value": 10,
"source": "bbb"
},
"condition_a":{
"name": "ccc",
"value": 20,
"source": "ddd"
},
"condition_b":{
"condition_c":{
"name": "ddd",
"value": 30,
"source": "eee"
},
"condition_c":{
"name": "fff",
"value": 40,
"source": "ggg"
}
}
}
It has unknown number of keys, some of them hold nested JSONs within them, some of them don't. The key names are also changing and unknown. In addition, it has duplicate keys, like condition_a is duplicated throughout the JSON but holds different values within.
I want to know how to parse this JSON onto a table that looks like this:
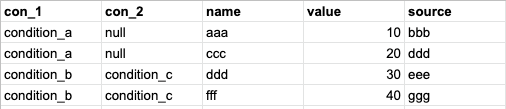
con_1 and con_2 are the number of levels of nested JSONs it found to be - which is also unknown!
Thank you in advance!
CodePudding user response:
Consider below approach
select
ifnull(con_1, con_2) con_1,
if(con_1 is null, null, con_2) con_2,
name, value, source
from (
select kv,
regexp_extract(norm_text, r'"([^"] )":{(?:"[^"] ":{[^{}] },)*' || kv || '.*}') con_1,
trim(split(kv, ':')[offset(0)], '"') con_2,
regexp_extract(kv, r'"name": "([^"] )"') name,
regexp_extract(kv, r'"value": (\d )') value,
regexp_extract(kv, r'"source": "([^"] )"') source,
from your_table,
unnest([regexp_replace(regexp_replace(regexp_replace(text, r'\n', ''), r'({|,)(\s )(")', r'\1\3'), r'(")(\s )(})', r'\1\3')]) norm_text,
unnest(regexp_extract_all(norm_text, r'"[^"] ":{\s*"name": "[^"] ",\s*"value": \d ,\s*"source": "[^"] "\s*}')) kv
)
if applied to sample data in your question - output is