I am working with the R programming language.
I trying to scrape the name, address and phone numbers of the pizza stores on this website :
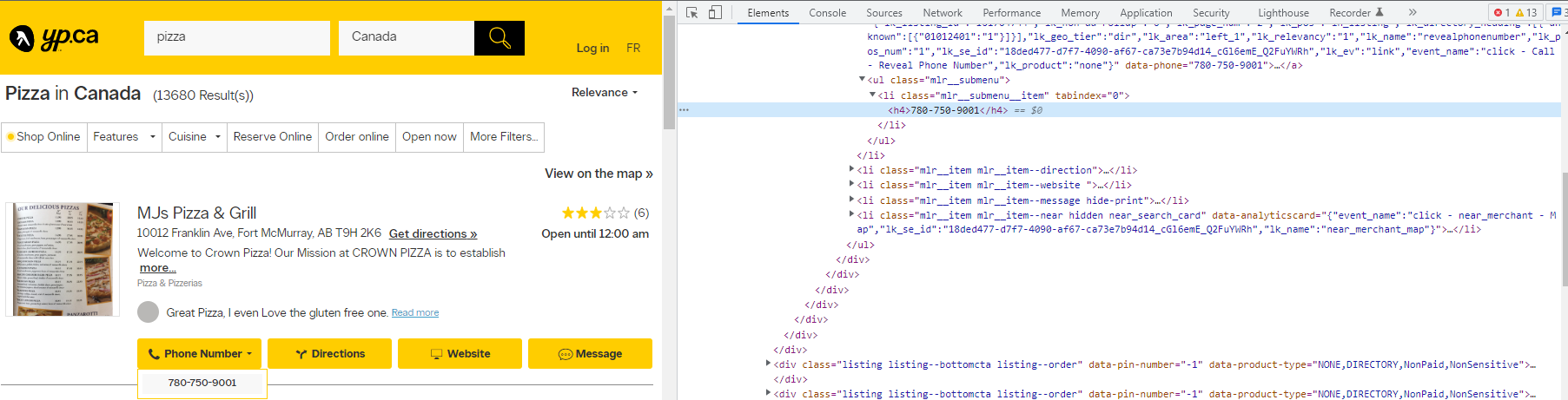
But I am not sure how I can include this specification in the existing webscraping code.
Can someone please show me how to do this?
Thanks!
CodePudding user response:
This is pretty straight forward. The key is to perform the parsing in two steps. First find the parent node for each business then extract out the phone number.
library(rvest) page<-read_html("https://www.yellowpages.ca/search/si/2/pizza/Canada") #get the individual business card nodes <- page %>% html_elements("div.listing_right_section") #find the phone number node phone <- nodes %>% html_element("ul h4") %>% html_text()In this case the phone numbers are within a "h4" tag underneath an "ul" tag.
Update
Incorporating the above code into your code:scraper <- function(url) { page <- url %>% read_html(url) #find the business records nodes businesses <- page %>% html_elements("div.listing_right_section") #now extract the request information from each node tibble( name = businesses %>% html_element(".jsListingName") %>% html_text2(), address = businesses %>% html_element(".listing__address--full") %>% html_text2(), phone = businesses %>% html_element("ul h4") %>% html_text() ) } name_address = scraper("https://www.yellowpages.ca/search/si/2/pizza/Canada")The key for successful scraping is to use
html_elements()to grab all of the parent nodes, each of which contain a full record. Then usehtml_element()(without the s) to grab the wanted field (child node) out of each parent node.
This will always work. Using html_elements will provide vectors with a variable number of elements if there is some missing information.CodePudding user response:
@ Dave2e: I took the code provided in your answer and tried to incorporate it into the existing code:
scraper <- function(url) { page <- url %>% read_html() tibble( name = page %>% html_elements(".jsListingName") %>% html_text2(), address = page %>% html_elements(".listing__address--full") %>% html_text2() ) } name_address = scraper("https://www.yellowpages.ca/search/si/2/pizza/Canada") library(rvest) page<-read_html("https://www.yellowpages.ca/search/si/2/pizza/Canada") #get the individual business card nodes <- page %>% html_elements("div.listing_right_section") #find the phone number node phone <- nodes %>% html_element("ul h4") %>% html_text() final = cbind(name_address, phone)Have I done this correctly? Is there a better way (e.g. more efficient) to do this?
Thank you so much!