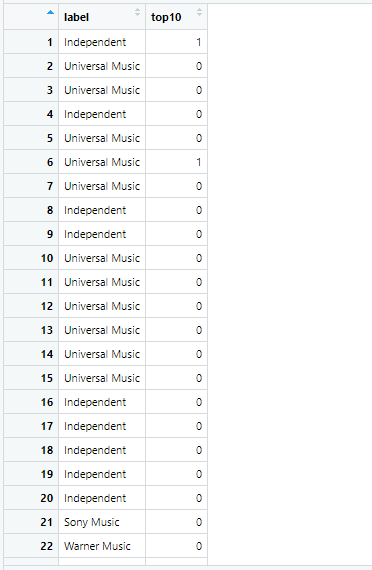
I have a dataframe, where the variable top10 has either value 0 (not in top 10) and 1 (in top 10). And a categorical variable label (Independent, Warner Music, Sony music, Universal music).
What would be an appropriate plot to visualize the relationship between these variables?
I was thinking about to visualize the probabilities of each label of being in top 10 (top10 == 1). But I have no idea how to do it...
That is what I started to do:

CodePudding user response:
There are many, many potential solutions to your problem. Perhaps this approach suits your use-case?
library(vcd)
#> Loading required package: grid
set.seed(300)
df <- data.frame(label = sample(c("Independent", "Warner Music", "Sony music", "Universal music"),
20, replace = TRUE),
top10 = as.character(sample(c(0, 0, 1), 20, replace = TRUE)))
df
#> label top10
#> 1 Warner Music 0
#> 2 Warner Music 1
#> 3 Warner Music 0
#> 4 Independent 0
#> 5 Universal music 0
#> 6 Independent 1
#> 7 Independent 1
#> 8 Universal music 0
#> 9 Sony music 1
#> 10 Independent 1
#> 11 Universal music 1
#> 12 Independent 0
#> 13 Universal music 0
#> 14 Sony music 0
#> 15 Universal music 1
#> 16 Sony music 1
#> 17 Universal music 1
#> 18 Universal music 0
#> 19 Independent 1
#> 20 Independent 0
mosaic(data = table(df), ~ label top10, highlighting = "top10",
highlighting_fill = c("lightblue", "pink"),
rot_labels=c(0,90,0,0), just_labels=c("left","right"))
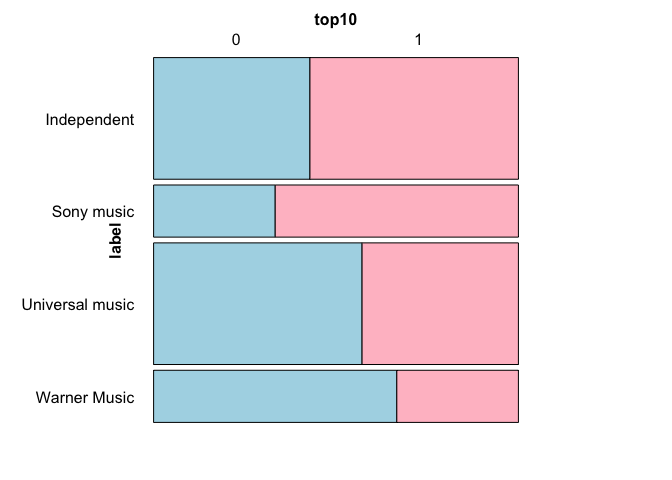
Created on 2022-11-15 by the 
You can of course pretty up the labels as you feel.