I have a text dataset that looks like this.
import pandas as pd
df = pd.DataFrame({'Sentence': ['Hello World',
'The quick brown fox jumps over the lazy dog.',
'Just some text to make third sentence!'
],
'label': ['greetings',
'dog,fox',
'some_class,someother_class'
]})
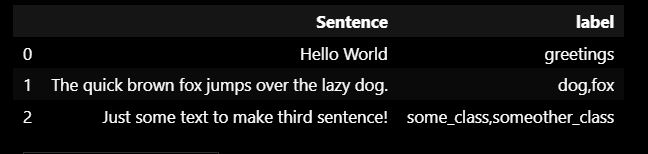
I want to transform this data into something like this.

Is there a pythonic way to make this transformation for multilabel classification?
CodePudding user response:
You can use pandas.Series.explode to explode the label column then cross it with the sentences column by using pandas.crosstab.
Try this :
def cross_labels(df):
return pd.crosstab(df["Sentence"], df["label"])
out = (
df.assign(label= df["label"].str.split(","))
.explode("label")
.pipe(cross_labels)
.rename_axis(None, axis=1)
.reset_index()
)
# Output :
print(out)
Sentence dog fox greetings some_class someother_class
0 Hello World 0 0 1 0 0
1 Just some text to make third sentence! 0 0 0 1 1
2 The quick brown fox jumps over the lazy dog. 1 1 0 0 0