We are porting some code from SSIS to Python. As part of this project, I'm recreating some packages but I'm having issues with the database access. I've managed to query the DB like this:
employees_table = (spark.read
.format("jdbc")
.option("url", "jdbc:sqlserver://dev.database.windows.net:1433;database=Employees;encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.database.windows.net;loginTimeout=30;")
.option("query", query)
.option("user", username)
.option("password", password)
.load()
)
With this I make API calls, and want to put the results into the DB, but everything I've tried causes errors.
df.write.method("append") \
.format("jdbc") \
.option("url", "jdbc:sqlserver://dev.database.windows.net:1433;database=Employees;encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.database.windows.net;loginTimeout=30;") \
.option("v_SQL_Insert", query) \
.option("user", username) \
.option("password", password) \
.option("query",v_SQL_Insert) \
.save()</p>
Gives me the error AttributeError: 'DataFrame' object has no attribute 'write'.
I get the same error using spark.write or if I try creating an actual dataframe, populate it and try to use the write function.
My question is, what is the best way to populate a db table from Python? Is it to create a dataframe and save it to the DB, or create an SQL command? And how do we go about sending that data in?
CodePudding user response:
Are you using Pandas by any chance? If df is not a Spark DataFrame you'll often see this error, most commonly if it's in fact a Pandas DataFrame (which, like the error message says, has no attribute 'write'.)
The Spark JDBC DataWriter tutorial code here works just fine
jdbcDF = spark.read \
.format("jdbc") \
.option("url", "jdbc:postgresql:dbserver") \
.option("dbtable", "schema.tablename") \
.option("user", "username") \
.option("password", "password") \
.load()
jdbcDF.write \
.format("jdbc") \
.option("url", "jdbc:postgresql:dbserver") \
.option("dbtable", "schema.tablename") \
.option("user", "username") \
.option("password", "password") \
.save()
So the main approach is:
- Create the PySpark DataFrame you wish to write to your database
- Write it to your database as a standalone staging table
- Optionally do additional ETL in destination database
CodePudding user response:
If you don't have a spark data frame you will get this error AttributeError: 'DataFrame' object has no attribute 'write'.
Please follow below syntax and steps to solve the above error. I tried to reproduce it in my environment and I got the below results:
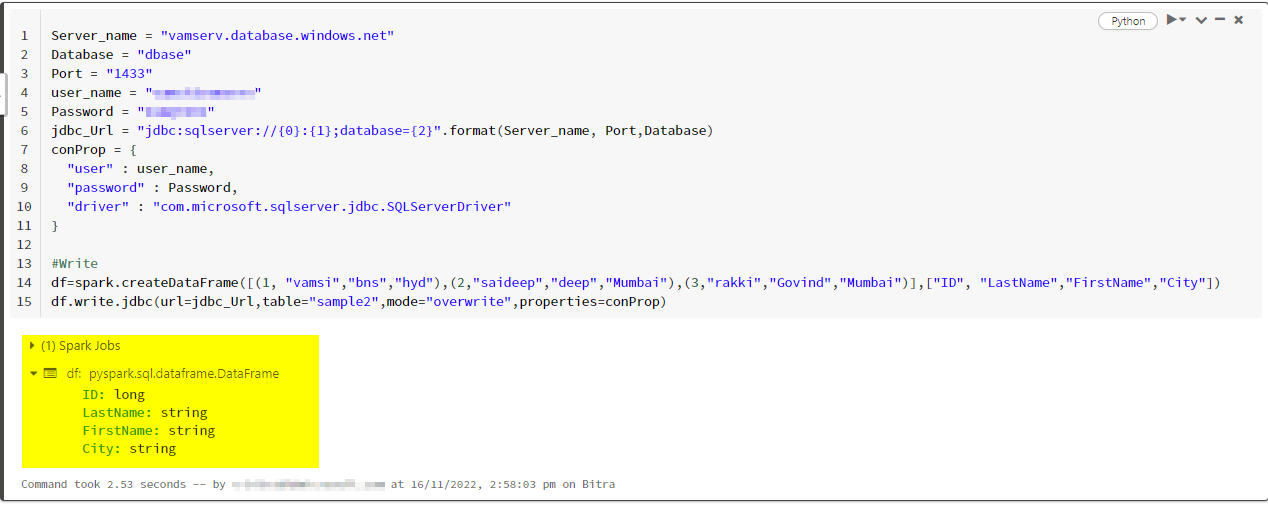
Server_name = "<server_name>.database.windows.net"
Database = "<database_name>"
Port = "1433"
user_name = "Your_username>"
Password = "<Password>"
jdbc_Url = "jdbc:sqlserver://{0}:{1};database={2}".format(Server_name, Port,Database)
conProp = {
"user" : user_name,
"password" : Password,
"driver" : "com.microsoft.sqlserver.jdbc.SQLServerDriver"
}
#Sample dataframe with Write operation
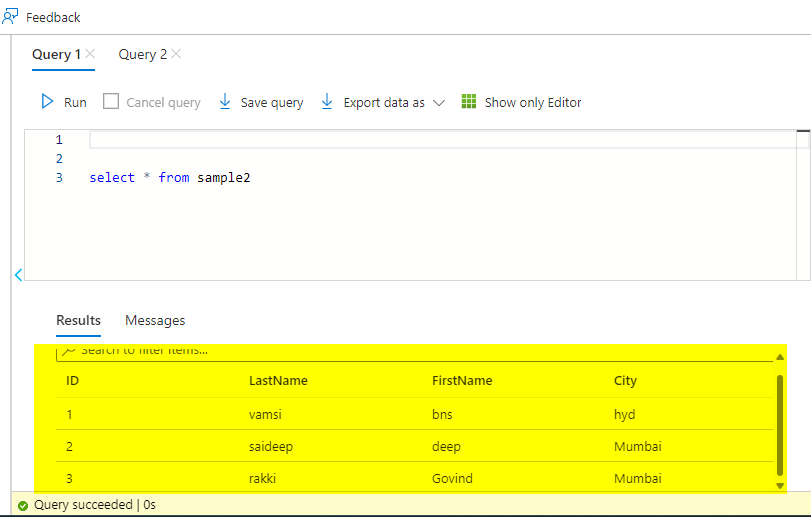
df=spark.createDataFrame([(1, "vamsi","bns","hyd"),(2,"saideep","deep","Mumbai"),(3,"rakki","Govind","Mumbai")],["ID", "LastName","FirstName","City"])
df.write.jdbc(url=jdbc_Url,table="sample2",mode="overwrite",properties=conProp)
Output: