Hello my problem is almost the same as this post : 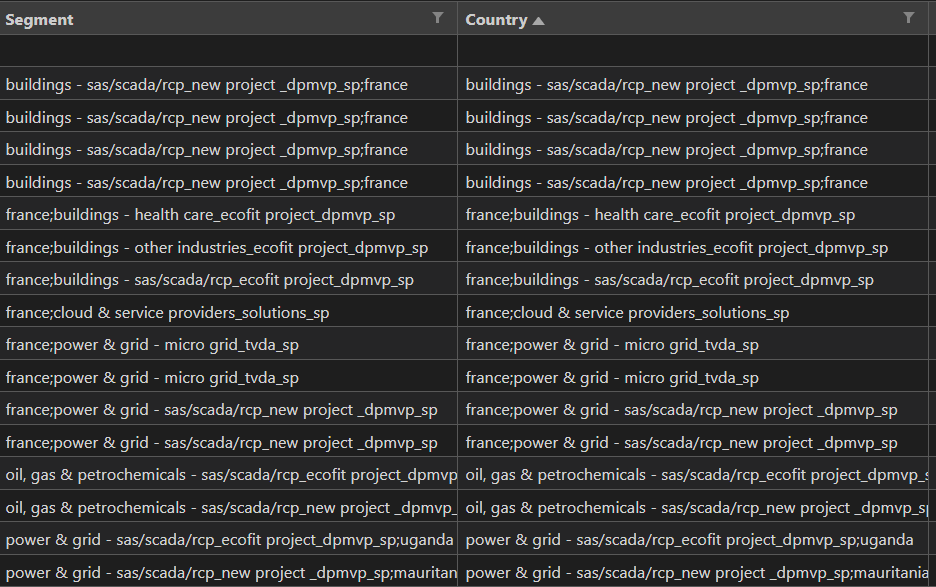 Originally I have this :
Originally I have this :
| Segment | Country | Segment 1 | Country 1 | Segment 2 |
|---|---|---|---|---|
| Nan | Nan | 123456 | 123456 | Nan |
| Nan | Nan | Nan | Nan | Nan |
| Nan | Nan | Nan | 123456 | 123456 |
| Nan | Nan | Nan | 123456 | 123456 |
Actually I have this (The first columns are filled by the two lines before the last in my code :
| Segment | Country | Segment 1 | Country 1 | Segment 2 |
|---|---|---|---|---|
| Seg1 ; Country1 ; | Seg1 ; Country1 ; | 123456 | 123456 | Nan |
| Nan | Nan | Nan | Nan | Nan |
| country1 ; seg2 ; | country1 ; seg2 ; | Nan | 123456 | 123456 |
| country1 ; seg2 ; | country1 ; seg2 ; | Nan | 123456 | 123456 |
And I need this :
| Segment | Country | Segment 1 | Country 1 | Segment 2 |
|---|---|---|---|---|
| Segment 1 | Country1 | 123456 | 123456 | Nan |
| Nan | Nan | Nan | Nan | Nan |
| Segment 2 | country1 | Nan | 123456 | 123456 |
| Segment 2 | country1 | Nan | 123456 | 123456 |
Edit : My code Actually look like that after trying to integrate the anwser :
Error is : AttributeError: Can only use .str accessor with string values!. Did you mean: 'std'?
#For each column in df, check if there is a value and if yes : first copy the value into the 'Amount' Column, then copy the column name into the 'Segment' or 'Country' columns
for column in df.columns[3:]:
valueList = df[column][3:].values
valueList = valueList[~pd.isna(valueList)]
def detect(d):
cols = d.columns.values
dd = pd.DataFrame(columns=cols, index=d.index.unique())
for col in cols:
s = d[col].loc[d[col].str.contains(col[0:3], case=False)].str.replace(r'(\w )(\d )', col r'\2')
dd[col] = s
return dd
#Fill amount Column with other columns values if NaN
if column in isSP:
df['Amount'].fillna(df[column], inplace = True)
df['Segment'] = df.iloc[:, 3:].notna().dot(df.columns[3:] ';' ).str.strip(';')
df['Country'] = df.iloc[:, 3:].notna().dot(df.columns[3:] ' ; ' ).str.strip(';')
df[['Segment', 'Country']] = detect(df[['Segment', 'Country']].apply(lambda x: x.astype(str).str.split(r'\s [ ]\s ').explode()))
Thank you very much.
CodePudding user response:
You can use the following solution. For this solution I first defined a custom function to filter your first two columns based on values that partially match the column name and then replace them with the full column name:
def detect(d):
cols = d.columns.values
dd = pd.DataFrame(columns=cols, index=d.index.unique())
for col in cols:
s = d[col].loc[d[col].str.contains(col[0:3], case=False)].str.replace(r'(\w )(\d )', col r'\2')
dd[col] = s
return dd
df[['Segment', 'Country']] = detect(df[['Segment', 'Country']].apply(lambda x: x.astype(str).str.split(';').explode()))
df
Segment Country Segment 1 Country 1 Segment 2
0 Segment1 Country1 123456 123456 Nan
1 NaN NaN Nan Nan Nan
2 Segment2 Country1 Nan 123456 123456
3 Segment2 Country1 Nan 123456 123456
CodePudding user response:
Given:
Segment Country Segment 1 Country 1 Segment 2
0 Seg1;Country1 Seg1;Country1 123456 123456 Nan
1 Nan Nan Nan Nan Nan
2 country1;seg2 country1;seg2 Nan 123456 123456
3 country1;seg2 country1;seg2 Nan 123456 123456
Doing
cols = ['Segment', 'Country']
df[cols] = df.Segment.str.split(';', expand=True)
is_segment = 'eg' # ~You'll used '_sp' here~
# Let's sort values with a custom key, namely,
# does the string (not) contain what we're looking for?
key = lambda x: ~x.str.contains(is_segment, na=False)
func = lambda x: x.sort_values(key=key, ignore_index=True)
df[cols] = df[cols].apply(func, axis=1)
print(df)
Output:
Segment Country Segment 1 Country 1 Segment 2
0 Seg1 Country1 123456 123456 Nan
1 Nan None Nan Nan Nan
2 seg2 country1 Nan 123456 123456
3 seg2 country1 Nan 123456 123456
Regex-heavy version:
pattern = '(?P<Segment>. eg\d);(?P<Country>. )|(?P<Country_>. );(?P<Segment_>. eg\d)'
extract = df.Segment.str.extract(pattern)
for col in cols:
df[col] = extract.filter(like=col).bfill(axis=1)[col]