I want to calculate the percentage change for the following data frame.
import pandas as pd
df = pd.DataFrame({'team': ['A', 'A', 'A', 'B', 'B', 'B', 'C', 'C'],
'points': [12, 0, 19, 22, 0, 25, 0, 30],
'score': [12, 0, 19, 22, 0, 25, 0, 30]
})
print(df)
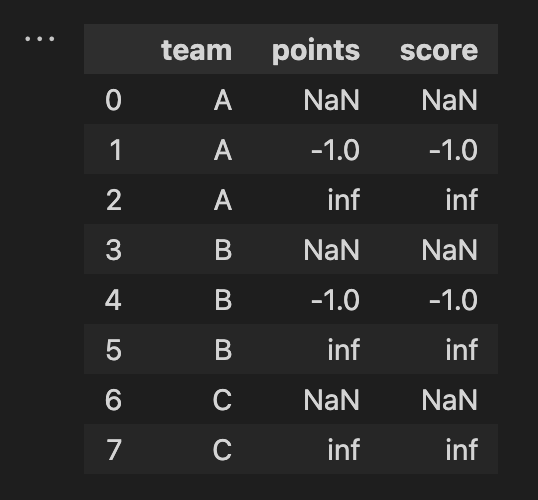
When I applied this step, it returns inf which is obvious because we are dividing by zero.
df['score'] = df.groupby('team', sort=False)['score'].apply(
lambda x: x.pct_change()).to_numpy()
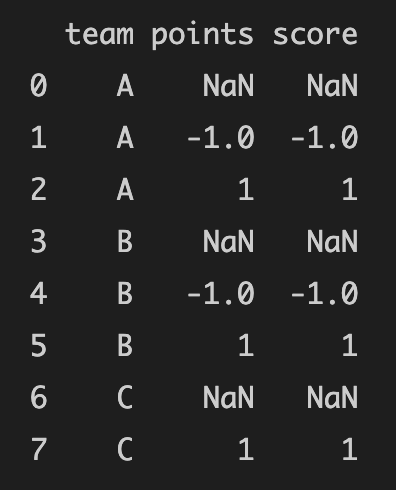
But if we see in each column the change from 0 to 19 the change is 100%, from 0 to 25 the change is 100%, and from 0 to 30 the change is 100%. So, I was wondering how can I calculate those values.
current result
Expected result is
CodePudding user response:
So you just want to replace the infinite values with 1?
import numpy as np
df[['points', 'score']] = (
df.groupby('team')
.pct_change()
.replace(np.inf, 1)
)
Output:
team points score
0 A NaN NaN
1 A -1.0 -1.0
2 A 1.0 1.0
3 B NaN NaN
4 B -1.0 -1.0
5 B 1.0 1.0
6 C NaN NaN
7 C 1.0 1.0
CodePudding user response:
# take the sign using np.sign for the diff b/w two consecutive rows
df['chg']=np.sign(df.groupby('team')['score'].diff())
df
team points score chg
0 A 12 12 NaN
1 A 0 0 -1.0
2 A 19 19 1.0
3 B 22 22 NaN
4 B 0 0 -1.0
5 B 25 25 1.0
6 C 0 0 NaN
7 C 30 30 1.0
CodePudding user response:
Not sure if you want to count the drops in score as a negative, but this will give you the calculation you're looking for (multiplying by 100 to get to how you're representing the percentages in your output). Basically, diff calculates the difference between current and prior.
df = pd.DataFrame({'team': ['A', 'A', 'A', 'B', 'B', 'B', 'C', 'C'],
'points': [12, 0, 19, 22, 0, 25, 0, 30],
'score': [12, 0, 19, 22, 0, 25, 0, 30]
})
df["score"] = df.groupby('team', sort=False)['score'].diff() * 100
print(df)
To set the rows to 1 / -1, simply use loc for positive / negative values and set accordingly like so
df.loc[df["score"] < 0, "score"] = -1
df.loc[df["score"] > 0, "score"] = 1