I'm pretty new to R and programming in general. I'm working on an assignment in R and I'm at a dead end with my current knowledge.
My data looks like this:
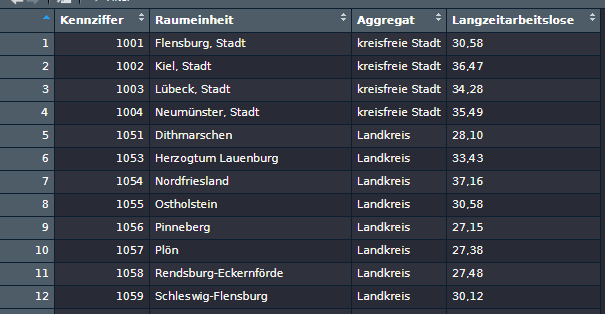
I'm using the tidyverse and I want to create a new table with the only entries being rows with the "Kennziffer" (first column) ranging from 1 to 10 in the first two numbers.
My try is it to use the command:
new_object <- table_name %>%
filter(table_name, Kennziffer == and I don't know what to put here to get values starting with 1 to 10
any help would be greatly appreciated.
Thanks for taking the time to read and answer.
I tried:
new_object <- table_name %>% filter(table_name, Kennziffer == 1,2,3,4,5,6,7,8,9,10)
but this doesn't work as the Kennziffer value is 4 or 5 characters long.
CodePudding user response:
You can use stringr::str_sub() to remove the last 3 digits and then ensure a match to your list of accepted start values (e.g. 1-10).
library(tidyverse)
d <- structure(list(Kennziffer = c(1001L, 1002L, 1003L, 1004L, 1051L, 1053L, 1054L, 1055L, 1056L, 1057L, 1058L, 1059L), Raumeinheit = c("Flensburg. Stadt", "Kiel. Stadt", "Lübeck. Stadt", "Neumünster. Stadt", "Dithmarschen", "Herzogtum Lauenburg", "Nordfriesland", "Ostholstein", "Pinneberg", "Plön", "Rendsburg-Eckernförde", "Schleswig-Flensburg"), Aggregat = c("kreisfreie Stadt", "kreisfreie Stadt", "kreisfreie Stadt", "kreisfreie Stadt", "Landkreis", "Landkreis", "Landkreis", "Landkreis", "Landkreis", "Landkreis", "Landkreis", "Landkreis"), Langzeitarbeitslose = c(30.58, 36.47, 34.28, 35.49, 28.1, 33.43, 37.16, 30.58, 27.15, 27.38, 27.48, 30.12)), class = "data.frame", row.names = c("1", "2", "3", "4", "5", "6", "7", "8", "9", "10", "11", "12"))
# create list of "first two digits" you want to match
digits2keep <- as.character(1:10)
# extract first 2 digits and filter to matches
d %>%
mutate(start_digits = str_sub(Kennziffer, 1, nchar(Kennziffer) - 3)) %>%
filter(start_digits %in% digits2keep)
#> Kennziffer Raumeinheit Aggregat Langzeitarbeitslose
#> 1 1001 Flensburg. Stadt kreisfreie Stadt 30.58
#> 2 1002 Kiel. Stadt kreisfreie Stadt 36.47
#> 3 1003 Lübeck. Stadt kreisfreie Stadt 34.28
#> 4 1004 Neumünster. Stadt kreisfreie Stadt 35.49
#> 5 1051 Dithmarschen Landkreis 28.10
#> 6 1053 Herzogtum Lauenburg Landkreis 33.43
#> 7 1054 Nordfriesland Landkreis 37.16
#> 8 1055 Ostholstein Landkreis 30.58
#> 9 1056 Pinneberg Landkreis 27.15
#> 10 1057 Plön Landkreis 27.38
#> 11 1058 Rendsburg-Eckernförde Landkreis 27.48
#> 12 1059 Schleswig-Flensburg Landkreis 30.12
#> start_digits
#> 1 1
#> 2 1
#> 3 1
#> 4 1
#> 5 1
#> 6 1
#> 7 1
#> 8 1
#> 9 1
#> 10 1
#> 11 1
#> 12 1
Created on 2022-11-22 with reprex v2.0.2
Although this seems unnecessarily complicated. Since Kennziffer is already numeric I can't see why d %>% filter(Kennziffer < 11000) wouldn't work.
CodePudding user response:
If I understand you correctly, We could use slice:
library(dplyr)
df %>%
slice(1:10)
Kennziffer Raumeinheit Aggregat Langzeitarbeitslose
1 1001 Flensburg. Stadt kreisfreie Stadt 30.58
2 1002 Kiel. Stadt kreisfreie Stadt 36.47
3 1003 Lübeck. Stadt kreisfreie Stadt 34.28
4 1004 Neumünster. Stadt kreisfreie Stadt 35.49
5 1051 Dithmarschen Landkreis 28.10
6 1053 Herzogtum Lauenburg Landkreis 33.43
7 1054 Nordfriesland Landkreis 37.16
8 1055 Ostholstein Landkreis 30.58
9 1056 Pinneberg Landkreis 27.15
10 1057 Plön Landkreis 27.38
or maybe you need this:
df %>%
mutate(helper = as.numeric(substr(Kennziffer, 1, 2))) %>%
filter(helper >=1 & helper >=10) %>%
select(-helper)
data:
df <- structure(list(Kennziffer = c(1001L, 1002L, 1003L, 1004L, 1051L,
1053L, 1054L, 1055L, 1056L, 1057L, 1058L, 1059L), Raumeinheit = c("Flensburg. Stadt",
"Kiel. Stadt", "Lübeck. Stadt", "Neumünster. Stadt", "Dithmarschen",
"Herzogtum Lauenburg", "Nordfriesland", "Ostholstein", "Pinneberg",
"Plön", "Rendsburg-Eckernförde", "Schleswig-Flensburg"), Aggregat = c("kreisfreie Stadt",
"kreisfreie Stadt", "kreisfreie Stadt", "kreisfreie Stadt", "Landkreis",
"Landkreis", "Landkreis", "Landkreis", "Landkreis", "Landkreis",
"Landkreis", "Landkreis"), Langzeitarbeitslose = c(30.58, 36.47,
34.28, 35.49, 28.1, 33.43, 37.16, 30.58, 27.15, 27.38, 27.48,
30.12)), class = "data.frame", row.names = c("1", "2", "3", "4",
"5", "6", "7", "8", "9", "10", "11", "12"))