I'm currently in the process of converting a SAS script to R. I'm quite familiar with R but not too much with SAS. I understand what the following code is trying to do but I haven't come across this type of indexing in R before and could really do with some guidance.
Below is the block of SAS code I am trying to convert to R:
data LA_5_c;
do index = 1 by 1 until(last.Entity_name);
do index = 1 by 1 until(last.Local_Authority);
set LA_5_B;
by business_reg_number Entity_name Local_Authority;
if index gt 3 then delete;
output; end; end;
run;
So I understand that we are creating a new index column based on the 2 variables Entity_name and Local_Authority. We don't want any index greater than 3 either which most likely corresponds to the fact there are 3 different years in the data.
I understand that if the Entity_name and Local_Authority repeat the same answers the rows will be indexed as 1, 2, 3, 1, 2, 3.... and so on. But also want to include cases where they don't repeat so periodically. Say if the Entity_name and Local_Authority changes after only 1 repetition so the index for this block would be 1, 2, 1....
So I understand what the code is trying to do I just don't know how to go about implementing this in R. I have looked into the setindexv() function and also using cbind along with nrow() to create an index column but I'm quite stumped as any combination I try isn't producing near what I want.
Any guidance would be much appreciated!
######## EDIT:
I have attached how I would like my data to look like below (result displayed in SAS but I would like in R. The original data is the same minus the Index column.
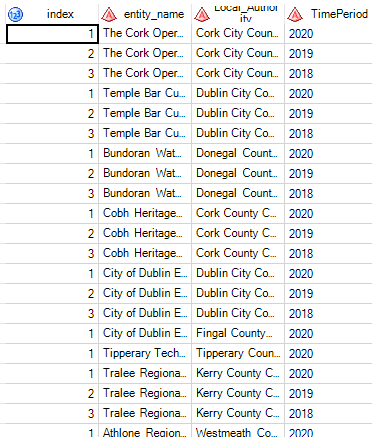
CodePudding user response:
It would be helpfull if you could post some sample data and the desired result, as this is not entirely clear to me.
However, this might already help you:
- group your dataset by Entity_name and Local_Authrority
- create a column with a constant value of 1, that serves as an intermediate helper variable.
- Calculate the index column using the
cumsum()function to calculate the cumulative total of the constant variable for each combination of Entity_name and Local_authority. This basicly means that if the value for the Entity_name and Local_authority column are repeated across subsequent rows, the index column takes the value of 1, 2, 3, ... . Whenever a new combination of Entity_name and Local_authority occurs, the value for the index column start counting from 1 onwards again. - Filter rows on index <= 3.
- Remove the constant column from the dataframe.
Below is an example with sample data:
First, create some sample data:
df <- data.frame("Entity_name" = c("A", "A", "A", "B", "B", "B", "B", "C", "D", "D"),
"Local_Authority" = c("F", "F", "F", "F", "G", "G", "G", "H", "I", "I"))
#Output:
> df
Entity_name Local_Authority
1 A F
2 A F
3 A F
4 B F
5 B G
6 B G
7 B G
8 C H
9 D I
10 D I
Next, create the index column using functions from the dplyr package.
library(dplyr)
df <- df %>%
arrange(Entity_name, Local_Authority) %>%
group_by(Entity_name, Local_Authority) %>%
mutate(constant = 1,
index = cumsum(constant)) %>%
filter(index <= 3) %>%
select(-constant)
The output looks like this:
Entity_name Local_Authority index
<chr> <chr> <dbl>
1 A F 1
2 A F 2
3 A F 3
4 B F 1
5 B G 1
6 B G 2
7 B G 3
8 C H 1
9 D I 1
10 D I 2