I've been through the array documentation in Big Query and found that I can use UNNEST and DISTINCT to remove duplicates in an array content, but I want to remove the duplicates only if they are adjacent in the array (as it's an ordered list).
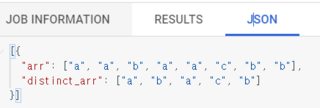
For example, for this input:
[a, a, b, a, a, c, b, b]
Expected output would be:
[a, b, a, c, b]
Any ideas appreciated.
CodePudding user response:
Use below approach
select *, array(
select any_value(el)
from (
select as struct *, countif(flag) over(order by offset) grp
from (
select offset, el, ifnull(el != lag(el) over(order by offset), true) flag
from t.arr as el with offset
)
)
group by grp
order by min(offset)
)
from your_table t
if applied to sample data in your question - output is
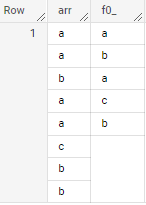
CodePudding user response:
You may consider another approach using set operation.
WITH sample_data AS (
SELECT ['a', 'a', 'b', 'a', 'a', 'c', 'b', 'b'] arr
)
SELECT *,
ARRAY(
SELECT e FROM (
SELECT e, o FROM t.arr e WITH offset o
EXCEPT DISTINCT
SELECT e, o 1 FROM t.arr e WITH offset o
) ORDER BY o
) AS distinct_arr
FROM sample_data t;
Query results