I have a vector of numbers called data with length 3205.
head(data,20)
[1] 225.43200 29.20875 329.46792 22.70996
[5] 80.84970 374.23959 343.11610 319.04798
[9] 2477.73200 72.79434 30.53376 92.39412
[13] 47.70744 52.30388 339.59634 1177.00448
[17] 48.27329 541.80997 38.45772 1568.93400
The density plot of this data looks like the following:
plot(density(data))
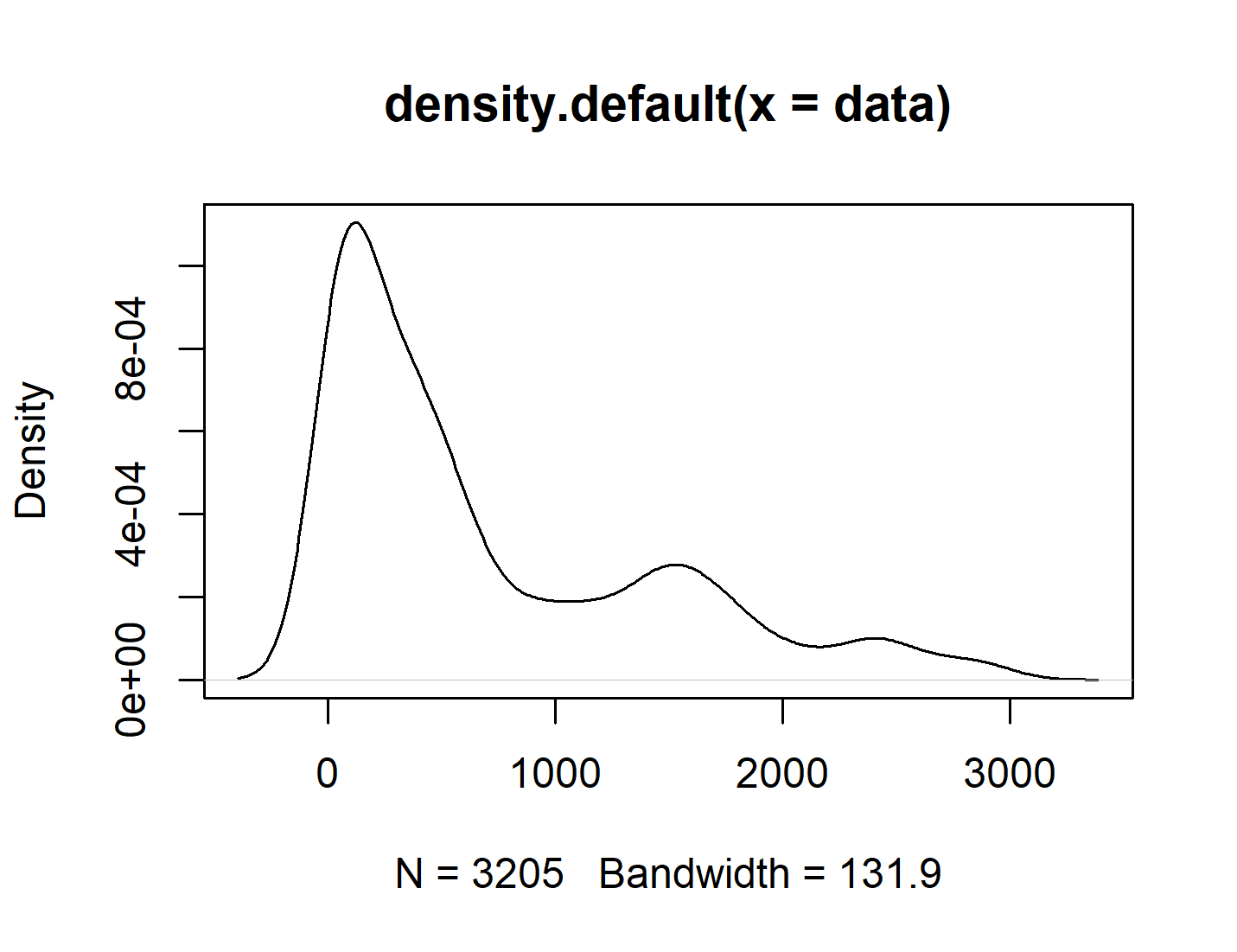
I would like to randomly sample a number given the distribution of this vector. Most of the times the number picked will be under 1000 but there is also a small chance of it being 1000-3000, and if we were to plot the density of the resultant sampled vector it would end up looking the same as this density plot. What would be the best way to do this?
CodePudding user response:
The accepted answer in Stackoverflow link given in a comment proposes to use the empirical cdf to perform the inverse sampling method. This is correct but there's a simplest way to achieve the same result: just pick some elements at random from the vector, with replacement.
Another possibility is to sample from a continuous distribution fitted to the distribution of your vector, using the kde1d package:
library(kde1d)
fit <- kde1d(data)
simulations <- rkde1d(1000, fit)