I have a df (reference image) that I create that shows an aggregation of all the combinations each publisher has to another and then does calculations based on said pair(s). 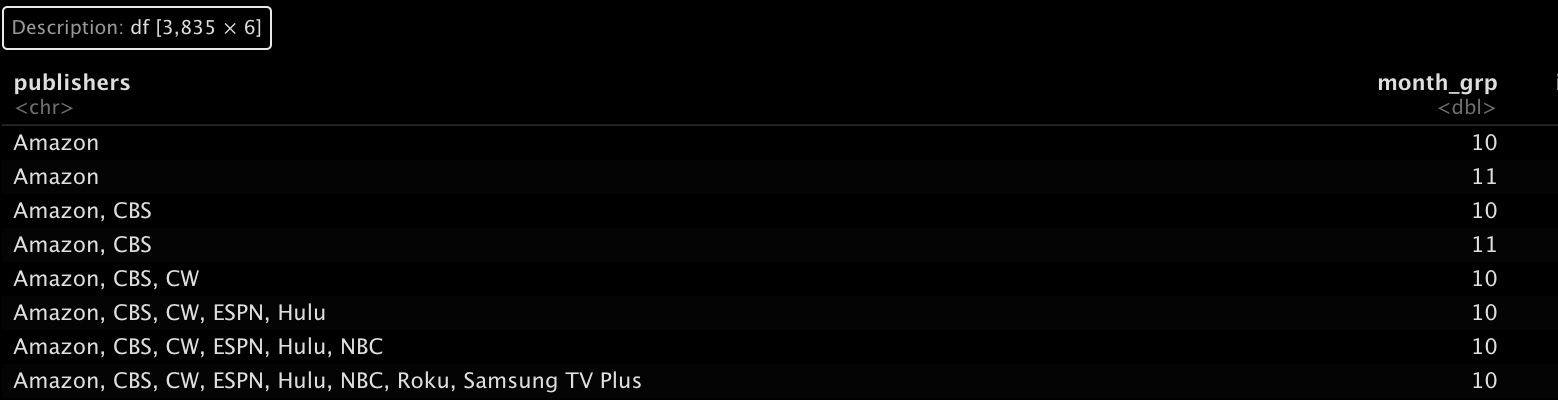
I want to pull every distinct pair that only contains 2 publishers and all the other field values that are tied to that pair (example would be Amazon, CBS but twice since there is one for month 10 and one for month 11 and so on.
How do I extract this or apply some dplyr function to only pull those? Was thinking of using a regex function in with a pipe but not sure how to do it.
Expected output
Publisher | month_grp
Amazon, CBS 10
Amazon, CBS 11
Amazon, CW 10
Amazon, CW 11
Amazon, ESPN 10
Amazon, ESPN 11
CodePudding user response:
I think that you want the rows with just one comma in the publishers column. You can get these using
df[grep('^[^,] ,[^,] $', df$publishers),]
CodePudding user response:
Similar answer to one posted seconds ago, but with dplyr::filter and stringr::str_detect:
library(tidyverse)
tribble(~ Publisher, ~month_grp,
"AWS, CBS", 4,
"AWS, CBS, CW", 2,
"AWS, ESPN", 6,
"AWS, CBS, ESPN", 2,
"AWS, Samsung TV plus", 4,
"AWS, ESPN, CBS", 4
) |>
filter(str_detect(Publisher, "^[\\w ]*, [\\w ]*$"))
#> # A tibble: 3 × 2
#> Publisher month_grp
#> <chr> <dbl>
#> 1 AWS, CBS 4
#> 2 AWS, ESPN 6
#> 3 AWS, Samsung TV plus 4