I'm newer to Python. I'm using openpyxl for a SEO project for my brother and I'm trying to get a number of rows that contain a specific value in them.
I have a spreadsheet that looks something like this:
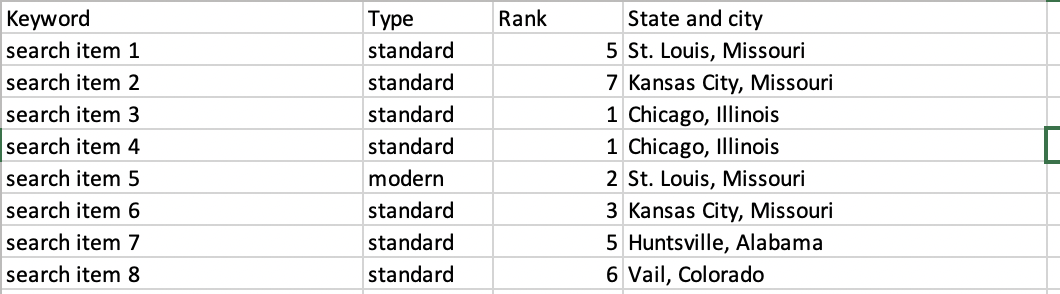
I want to write a program that will get the keywords and parse them to a string by state, so like: Missouri = "search item 1, search item 2, search item 5, search item 6" Illinois = "search item 3, search item 4"
I have thus far created a program like this:
#first, import openpyxl
import openpyxl
#next, give location of file
path = "testExcel.xlsx"
#Open workbook by creating object
wb_object = openpyxl.load_workbook(path)
#Get workbook active sheet object
sheet_object = wb_object.active
#Getting the value of maximum rows
#and column
row = sheet_object.max_row
column = sheet_object.max_column
print("Total Rows:", row)
print("Total Columns:", column)
#printing the value of forth column, state
#Loop will print all values
#of first column
print("\nValue of fourth column")
for i in range(4, row 1):
cell_object = sheet_object.cell(row=i, column=4)
split_item_test = cell_object.value.split(",")
split_item_test_result = split_item_test[0]
state = split_item_test_result
print(state)
if (state == 'Missouri'):
print(state.count('Missouri'))
print("All good")
The problem is after doing this, I see that it prints 1 repeatedly, but not a total number for Missouri. I would like a total number of mentions of the state, and then eventually get it to a string with each search criteria.
Is this possible with openpyxl? Or will I need a different library?
CodePudding user response:
ranemirusG is right, there are several ways to obtain the same result. Here's another option...I attempted to preserve your thought process, good luck.
print("\nValue of fourth column")
missouri_list = [] # empty list
illinois_list = [] # empty list
for i in range(2, row 1): # It didn't look like "4, row 1" captured the full sheet, try (2, row 1)
cell_object = sheet_object.cell(row=i, column=4)
keyword = sheet_object.cell(row=i, column=1)
keyword_fmt = keyword.value # Captures values in Keyword column
split_item_test = cell_object.value.split(",")
split_item_test_result = split_item_test[1] # 1 captures states
state = split_item_test_result
print(state)
# simple if statement to capture results in a list
if 'Missouri' in state:
missouri_list.append(keyword_fmt)
if 'Illinois' in state:
illinois_list.append(keyword_fmt)
print(missouri_list)
print(len(missouri_list)) # Counts the number of occurances
print(illinois_list)
print(len(illinois_list)) # Counts the number of occurances
print("All good")
CodePudding user response:
Yes, it's possible to do it with openpyxl.
To achieve your real goal try something like this:
states_and_keywords = {}
for i in range(4, row 1):
cell_object = sheet_object.cell(row=i, column=4)
split_item_test = cell_object.value.split(",")
split_item_test_result = split_item_test[1] #note that the element should be 1 for the state
state = split_item_test_result.strip(" ") #trim whitespace (after comma)
keyword = cell_object.offset(0,-3).value #this gets the value of the keyword for that row
if state not in states_and_keywords:
states_and_keywords[state] = [keyword]
else:
states_and_keywords[state].append(keyword)
print(states_and_keywords)