I have a file with multiple columns. I want to check the following conditions :
file.csv
A.B.P;FATH;FNAME;XTRUC;XIZE;XIZE2;ORG;ORG2
AIT;Y9A;RAIT;UNKNOWN;UNKNOWN;80;X;XY
AIT-A;Y9A;RAIT;VIR;67;217;X;X
- if $4 contains
UNKNOWNprint in a newerrorcolumn "XTRUCis UNKNOWN "
Example :
A.B.P;FATH;FNAME;XTRUC;XIZE;XIZE2;ORG;ORG2;error
AIT;Y9A;RAIT;UNKNOWN;UNKNOWN;80;X;XY;"XTRUC is UNKNOWN."
- if for the same value in $3 we have different values in $4 print in a new column "multiple
XTRUCvalue for the sameFNAME" and if the previous error exist print the new error in a new line in the same cell.
Example :
A.B.P;FATH;FNAME;XTRUC;XIZE;XIZE2;ORG;ORG2;error
AIT;Y9A;RAIT;UNKNOWN;UNKNOWN;80;X;XY;"XTRUC is UNKNOWN.
multiple XTRUC value for the same FNAME."
AIT-A;Y9A;RAIT;VIR;67;217;X;X;"multiple XTRUC value for the same FNAME"
- if $5 and $6 do not match or one of them or both contain something other tan numbers print the error in a new column "
XIZENOK" and/or "XIZE2 NOK" and/or "XIZE and XIZE2 don't match" in a new line if previous errors exist in the same cell.
Example :
A.B.P;FATH;FNAME;XTRUC;XIZE;XIZE2;ORG;ORG2;error
AIT;Y9A;RAIT;UNKNOWN;UNKNOWN;80;X;XY;"XTRUC is UNKNOWN.
multiple XTRUC value for the same FNAME.
XIZE NOK."
AIT-A;Y9A;RAIT;VIR;67;217;X;X;"multiple XTRUC value for the same FNAME.
XIZE and XIZE2 don't match."
- if $7 and $8 do not match print the error in a new column "ORG and ORG2 don't match" in a new line if previous errors exist in the same cell.
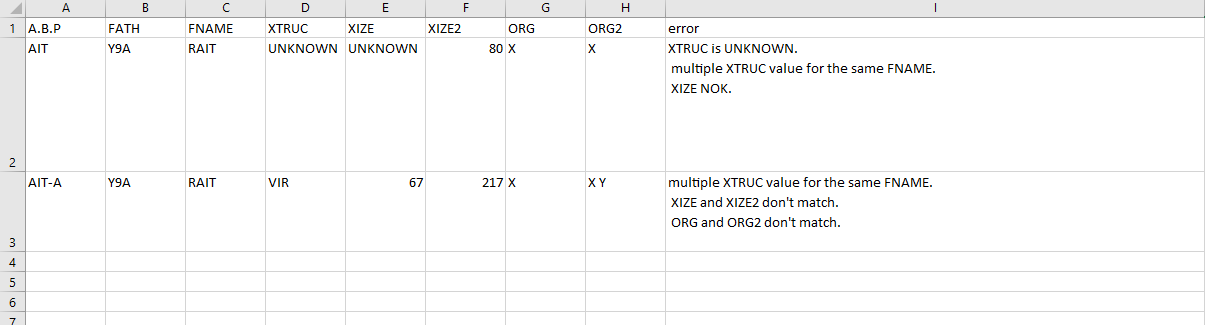
Example and expected result:
A.B.P;FATH;FNAME;XTRUC;XIZE;XIZE2;ORG;ORG2;error
AIT;Y9A;RAIT;UNKNOWN;UNKNOWN;80;X;X;"XTRUC is UNKNOWN.
multiple XTRUC value for the same FNAME.
XIZE NOK."
AIT-A;Y9A;RAIT;VIR;67;217;X;X Y;"multiple XTRUC value for the same FNAME.
XIZE and XIZE2 don't match.
ORG and ORG2 don't match."
Visual result from CSV file :
I tried to use multiple awk commands like :
awk '{if($5!=$6) print "XIZE and XIZE2 do not match" ; elif($5!='^[0-9] $' print "`XIZE` NOK" ; elif($6!="^-\?[0-9] $" print "`XIZE` NOK"}' file.csv
It didn't work and with multiple conditions i wonder if there's a simpler way to do it.
CodePudding user response:
I assume you want to add these messages to a new final column.
awk -F ';' 'BEGIN {OFS = FS}
{new_field = NF 1}
$5 != $6 {$new_field = $new_field "XIZE and XIZE2 do not match\n"}
$5 !~ "^[0-9] $" {$new_field = $new_field "`XIZE` NOK\n"}
$6 !~ "^-\\?[0-9] $" {$new_field = $new_field "`XIZE` NOK\n"}
{print}' file.csv > new-file.csv
This may output more newlines than you want. If that's a problem, it's possible to fix that, perhaps using an array and a for loop or building a string and adding it at print time (see below) instead of simple concatenation.
This script
- sets the field delimiter for input (
-F) and output (OFS) to a semicolon - calculates the field number of a new error field at the end of the row, it does this for each row, so it may be different if the lengths of rows varies
- for each true field test it concatenates a message to the error field
- regex tests use the negated regex match operator
!~ - each field in each row is tested (tests are not mutually exclusive (no
else), if you want them to be mutually exclusive you can change the form of the tests back to usingifandelse - prints the whole row whether an error field was added or not
- redirects the output to a new file
I used the shorter messages from your AWK script rather than the longer ones in your examples. You can easily change them if needed.
Here is an array version that eliminates an excess newline and wraps the new field in quotes:
awk -F ';' 'BEGIN {OFS = FS}
NR == 1 {print; next}
{new_field = NF 1; delete arr; i = 0; d = ""; msg = ""}
$5 != $6 {arr[i ] = "XIZE and XIZE2 do not match"}
$5 !~ "^[0-9] $" {arr[i ] = "`XIZE` NOK"}
$6 !~ "^-\\?[0-9] $" {arr[i ] = "`XIZE` NOK"}
{
if (i > 0) {
msg = "\"";
for (idx in arr) {
msg = d msg arr[idx];
d = "\n";
}
msg = msg "\"";
$new_field = msg;
};
print
}' file.csv > new-file.csv
CodePudding user response:
printf "AIT;Y9A;RAIT;UNKNOWN;UNKNOWN;80;X;XY" | tr ';' '\n' > stack
[[ $(sed -n '/UNKNOWN/p' stack) ]] && printf "\"XTRUC is UNKNOWN\"" >> stack
tr '\n' ';' < stack > s2
You can do the same thing with whatever other tests you like. Just replace the semi colons with newlines, and then use ed or sed to read the line number corresponding with the line you want. After that, replace the newlines with semicolons again.