in a web scraping project I wanted to collect some data from 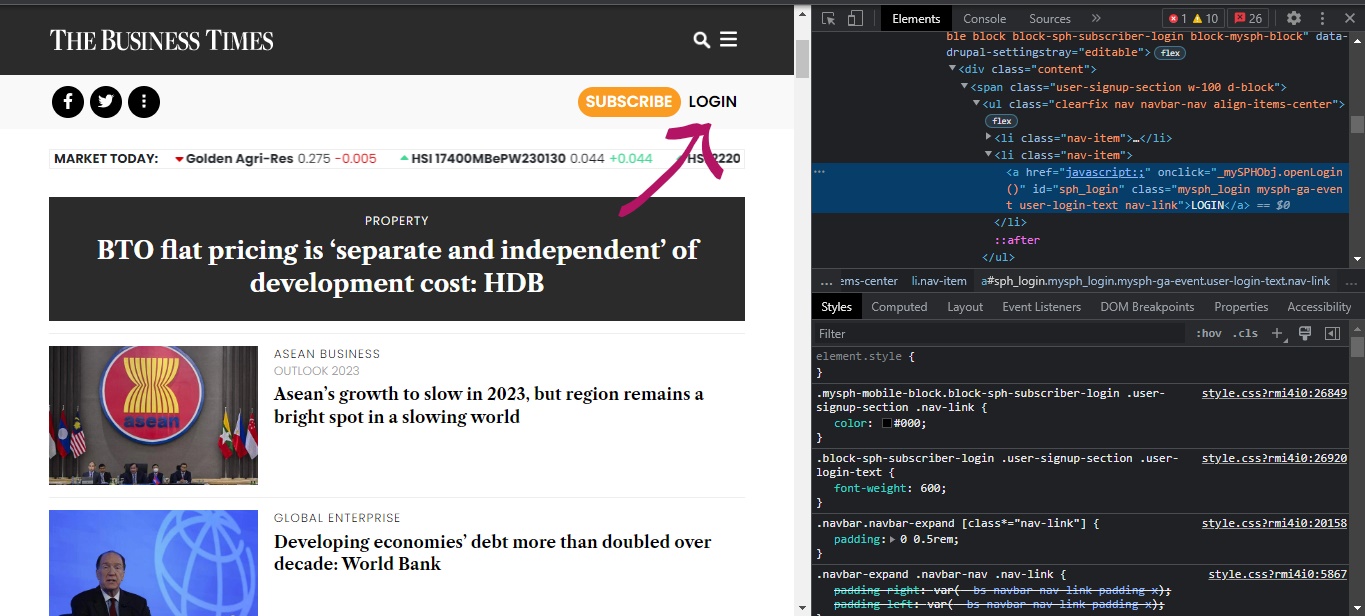
I tried with the CSS_Selector, Class_Name, By.ID methods too, apart from this XPATH method to select the button, but I didn't get success.
Here is my code,
def login_in(login_url):
options = webdriver.ChromeOptions()
lists = ['disable-popup-blocking']
caps = DesiredCapabilities().CHROME
caps["pageLoadStrategy"] = "normal"
options.add_argument("--window-size=1920,1080")
options.add_argument("--disable-extensions")
options.add_argument("--disable-notifications")
options.add_argument("--disable-Advertisement")
options.add_argument("--disable-popup-blocking")
username = 'insert_username'
password = 'insert_password'
driver = webdriver.Chrome(executable_path= r"E:\chromedriver\chromedriver.exe", options=options) #add your chrome path
driver.get(login_url)
button = driver.find_element(By.XPATH, '//*[@id="sph_login"]')
driver.execute_script("arguments[0].click();", button)
time.sleep(3)
driver.find_element(By.ID, "IDToken1").send_keys(username) # input user name
time.sleep(5)
driver.find_element(By.ID, "IDToken2").send_keys(password) # input password
time.sleep(2)
loginbutton = driver.find_element(By.ID, "btnLogin")
driver.execute_script("arguments[0].click();", loginbutton)
return driver
login_in('https://www.businesstimes.com.sg/')
Please help me with this. Thank you!
CodePudding user response:
you do not need to click the button. The button has an onclick attribut so you can just do this:
driver.execute_script("_mySPHObj.openLogin()")
and the login popup will open.
CodePudding user response:
There are more than one matches for your XPath, that's why the link is not getting clicked, try the below XPath:
driver.find_element(By.XPATH, ".//*[@class='user-signup-section w-100 d-block']//a[text()='LOG IN']").click()