I want to transform a dataset consisting of 189 rows from this:
(base)

to this: (desired result)

My idea was to use df.groupby('country').T
Which I think leads into the correct direction:
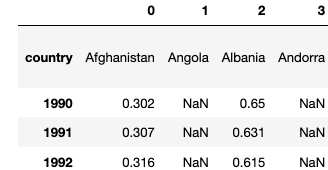
But it is not the intended result.
I want the first row to be a column – like in the first image above.
So I tried df['country'] = df.iloc[0] leading just to the same result as above (last image)
despite of the different column names which I know how to handle I want the base dataframe to be like the result frame. Is it actually an transposing issue – or something else? The desired columns are just: 'country', 'year' and 'hdi'
CodePudding user response:
With the following toy dataframe:
import pandas as pd
df = pd.DataFrame(
{
"country": ["Afghanistan", "Angola"],
1990: [0.302, 0.405],
1991: [0.307, 0.412],
1992: [0.316, 0.419],
}
)
print(df)
# Output
country 1990 1991 1992
0 Afghanistan 0.302 0.307 0.316
1 Angola 0.405 0.412 0.419
Here is one way to do it with Pandas groupby and stack:
df = (
df
.groupby("country")
.agg(list)
.applymap(lambda x: x[0])
.stack()
.reset_index()
.rename(columns={"level_1": "year", 0: "hdi"})
)
Then:
print(df)
# Output
country year hdi
0 Afghanistan 1990 0.302
1 Afghanistan 1991 0.307
2 Afghanistan 1992 0.316
3 Angola 1990 0.405
4 Angola 1991 0.412
5 Angola 1992 0.419