I have an excel file which I am using pd.read_excel() to read, inside the excel file are couple of date columns (the date data type is a string and must follow this format: dd/mm/yyyy. The problem I have is that when the excel file gets converted to a dataframe using pd.read_excel(), the values gets converted into an integer.
Does anyone know how I can maintain the value in the excel file after it has been converted to a dataframe.
Screenshot below:
The columns with the date format
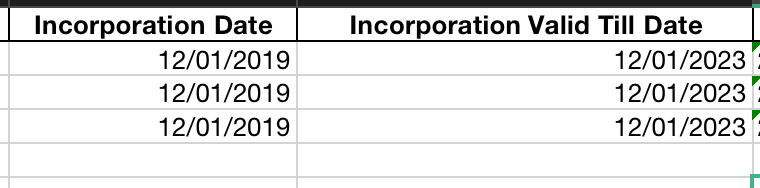
What the values get converted to after converting the file to a dataframe
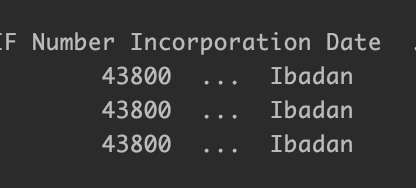
"43800" is what the value of "Incorporation Date" got converted to.
What I have tried:
for column in columns_with_date_string:
client_entity_df[column] = pd.to_datetime(
client_entity_df[column].astype(int)
)
client_entity_df[column] = client_entity_df[column].dt.strftime('%d/%m/%Y')
This approach returned the values as "01/01/1970", instead of the dates specified
TLDR:
I basically want to maintain the value of my date columns (12/11/2022) in my excel file where the format is "dd/mm/yyy" when the excel file gets converted to a dataframe, pandas currently changes the values to an integer (which I assume is an epoch) when it converts the file to an integer.
CodePudding user response:
You can use:
df_excel = pd.read_excel(file, dtype=object)
All columns became a object type and after that you can convert in another type if you need:
pd.to_datetime(df_excel['column_name'])
CodePudding user response:
So I got a solution to it:
for column in columns_with_date_string:
df[column] = df[column].apply(
lambda x: datetime.fromordinal(datetime(1900, 1, 1).toordinal() int(x) - 2)
)
df[column] = df[column].dt.strftime('%m/%d/%Y')
This SO answer was helpful.