There is a table, has 10 million records, and it has a column which type is array, it looks like:
id | content | contained_special_ids
----------------------------------------
1 | abc | { 1, 2 }
2 | abd | { 1, 3 }
3 | abe | { 1, 4 }
4 | abf | { 3 }
5 | abg | { 2 }
6 | abh | { 3 }
and I want to know that how many records there is which contained_special_ids includes 3, so my sql is:
select count(*) from my_table where contained_special_ids @> array[3]
It works fine when data is small, however it takes long time (about 30 seconds) when the table has 10 million records.
I have added index to this column:
"index_my_table_on_contained_special_ids" gin (contained_special_ids)
So, how to optimize this select count query?
Thanks a lot!
UPDATE
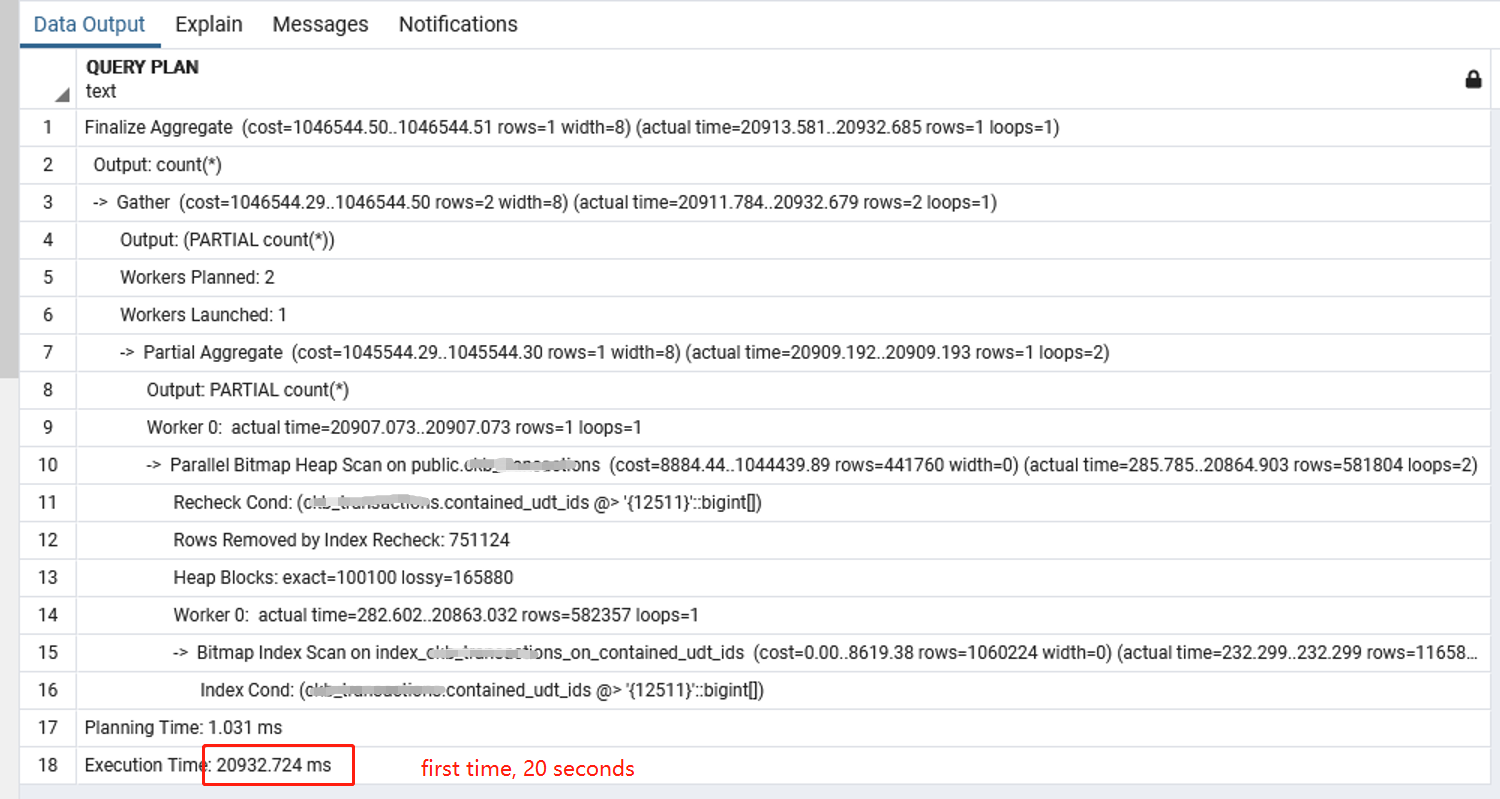
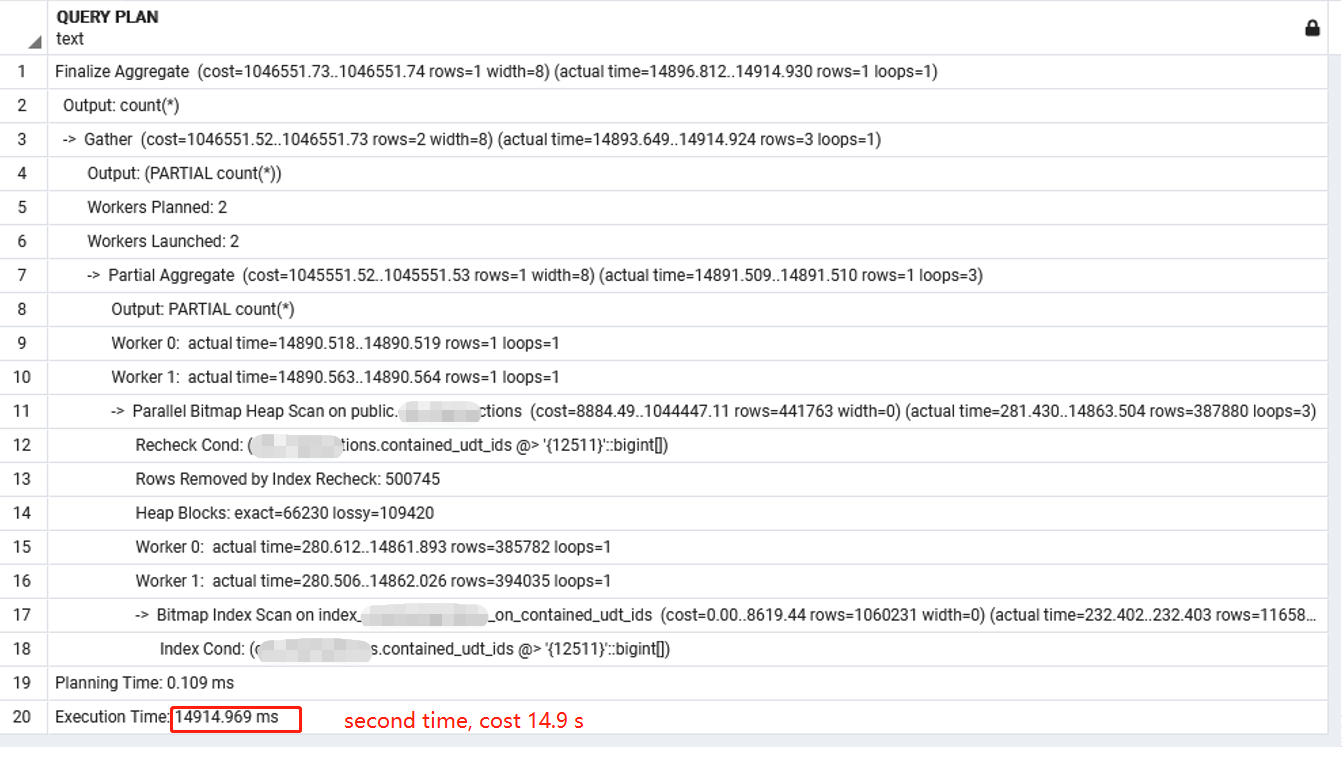
below is the explain:
picture version:
CodePudding user response:
Increase work_mem until the lossy blocks go away. Also, make sure the table is well vacuumed to support index-only bitmap scans, and that you are using a new enough version (which you should tell us) to support those. Finally, you can try increasing effective_io_concurrency.
Also, post plans as text, not images; and turn on track_io_timing.
CodePudding user response:
There is no way to optimize such a query due to 2 factors :
- The use of a non atomic value that violate the FIRST NORMAL FORM
- The fact that PostGreSQL is unable to perform quickly aggregate computation
On the first problem... 1st NORMAL FORM each data in table's colums must be atomic.... Of course an array containing multiple value is not atomic.
Then no index would be efficient on such a column due to a type that violate 1FN
This can be reduced by using a table instaed of an array
On the poor performance of PG's aggregate
PG use a model of MVCC that combine in the same table data pages with phantom records and valid records, so to count valid record, that's need to red one by one all the records to distinguish wich one are valid to be counted from the other taht must not be count... Most of other DBMS does not works as PG, like Oracle or SQL Server that does not keep phantom records inside the datapages, and some others have the exact count of the valid rows into the page header...
As a example, read the tests I have done comparing COUNT and other aggregate functions between PG and SQL Server, some queries runs 1500 time faster on SQL Server...