Can someone please help me solve a problem that I'm having with MySQL and REGEXP?
I am working on cleaning MySQL table containing vehicle inventory. The table has several million rows. I am trying to come up with a regex pattern that will find repeated words in each cell and replace only one of them with a SPACE character keeping the other. Here is an example of my table. There are many more columns in that table, but I only included a few for demonstration purpose.
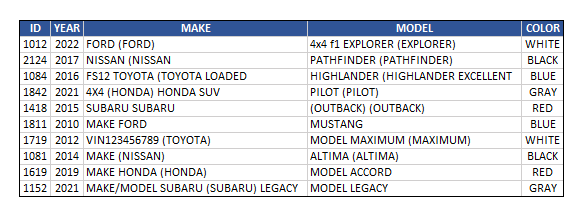
If you notice, the 2 columns MAKE and MODEL contain repeated words (i.e. "FORD FORD", "TOYOTA TOYOTA" etc.). This table was loaded from an old Excel file that used to be maintained manually. As you can see, the data is extremely dirty. I'm trying to do as much cleaning as possible to standardize the data. I want to keep only one copy of each repeated word removing the duplicates (i.e. "FORD", "TOYOTA", "NISSAN" etc.).
I was able to solve this problem partially (see code below):
update t_inventory
set make = trim(regexp_replace(make, '(\\([A-Za-z] \\))', ' '))
where make regexp '^([A-Za-z] )([^a-zA-Z0-9] )(\\([A-Za-z] \\))'
and mid(make, 1, instr(make, '(') - 2) =
mid(make, instr(make, '(') 1, instr(make, ')') - instr(make, '(') - 1);
The above code solves the problem for the values like "FORD (FORD)" or "TOYOTA (TOYOTA)" where first word is unwrapped, second word is inside parentheses and no other leading or trailing characters. But when I have a string like "MAKE NISSAN (NISSAN)" the above code won't work. It will replace word NISSAN with SPACE leaving only word MAKE.
Is there any way to write a single REGEXP pattern to remove all repeated words only keeping one? I don't even care if parentheses are kept. I can easily clean them later.
You'll probably ask why not find all possible garbage, create a dictionary and then write a procedure to filter it out. Yes, it would be ideal if the table had a few hundred to a few thousand rows. But my table has millions of rows. As I mentioned above, this data was migrated from Excel file that was maintained manually for over 20 years. It's hard to imagine how dirty the data there is. What you see in the diagram above is as simple as it can get. I wouldn't have asked for help if it wasn't as complex.
I really appreciate your help. Thank you so much in advance!
CodePudding user response:
Dirty data is often too chaotic to fix in a single UPDATE.
Answer: use more than one UPDATE!
UPDATE t_inventory
SET make = TRIM(LEADING 'MAKE' FROM make);
UPDATE t_inventory
SET make = REPLACE(make, 'FORD (FORD)', 'FORD');
UPDATE t_inventory
SET make = REPLACE(make, 'NISSAN (NISSAN)', 'NISSAN');
UPDATE t_inventory
SET make = REPLACE(make, 'HONDA (HONDA)', 'HONDA');
...and so on...
Every such edit is very simple to write.
You will probably now ask if you can also change NISSAN (NISSAN in the same UPDATE.
You're still thinking about combining the edits! Stop that. Just do multiple edits.
UPDATE t_inventory
SET make = REPLACE(make, 'NISSAN (NISSAN', 'NISSAN');
It does take longer to execute multiple edits. I understand you said your table has millions of rows. But if you compare to the time it takes you to develop a clever way of combining the edits, it's probably a wash. Besides, computers are good at executing the change over the millions of rows. You just have to wait for it to finish.
CodePudding user response:
mysql> SELECT REGEXP_REPLACE("FORD (FORD)", '\\b(\\w )\\b(.*)\\b(\\1)\\b(.*)$', '$1$2$4');
-----------------------------------------------------------------------------
| REGEXP_REPLACE("FORD (FORD)", '\\b(\\w )\\b(.*)\\b(\\1)\\b(.*)$', '$1$2$4') |
-----------------------------------------------------------------------------
| FORD () |
-----------------------------------------------------------------------------
That used version 8.0.31; another version may have different syntax.
Note that the replacement rebuilt the string without the second (that is $3) copy of 'FORD'.
Explaining some things:
\\b -- word boundary (start or end)
(...) -- capture what the insides matched into $1, $2, etc
\\w -- any string of letters
.* -- a string of anything ('greedy' version)
\\1 -- match what the first (1) "(...)" matched
$ -- anchored at the end (Probably unnecessary)
and on the replacement side:
$n -- the nth (...) matched
The example with 3 NISSANs gets a lot messier. The .* probably sent sailing through the second copy. .*? is "non-greedy"; that does replace the second NISSAN:
-----------------------------------------------------------------------------------------------------------------------
| REGEXP_REPLACE("NISSAN ALTIMA (NISSAN WHITE 2019 ) (NISSAN WHITE 2019",
'\\b(\\w )\\b(.*)\\b(\\1)\\b(.*)$', '$1$2$4') |
-----------------------------------------------------------------------------------------------------------------------
| NISSAN ALTIMA (NISSAN WHITE 2019 ) ( WHITE 2019 |
-----------------------------------------------------------------------------------------------------------------------
1 row in set (0.00 sec)
------------------------------------------------------------------------------------------------------------------------
| REGEXP_REPLACE("NISSAN ALTIMA (NISSAN WHITE 2019 ) (NISSAN WHITE 2019",
'\\b(\\w )\\b(.*?)\\b(\\1)\\b(.*)$', '$1$2$4') |
------------------------------------------------------------------------------------------------------------------------
| NISSAN ALTIMA ( WHITE 2019 ) (NISSAN WHITE 2019 |
------------------------------------------------------------------------------------------------------------------------
Plan A: One approach is to run two UPDATEs, one to handle 2-copy rows, and another to handle 3-copy rows.
Plan B: Alternatively, some kind of looping mechanism. This could be done with a Stored Procedure and probably some different functions, such as SUBSTRING_INDEX().
Plan C: The third (and arguably best) is to pull the data into your app which probably has better string and regexp handling capabilities.