I have multiple csv files in the below format:
CSV File 1:
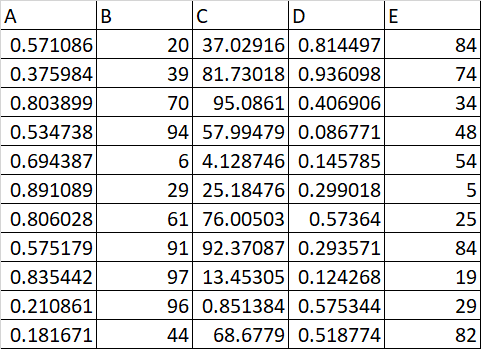
CSV File 2:
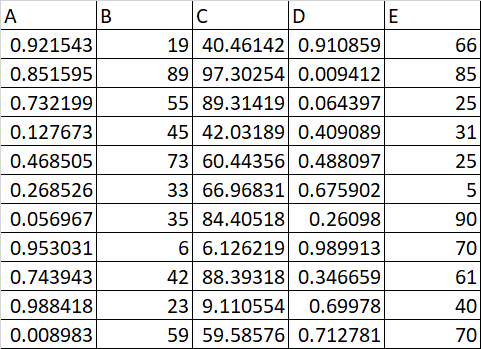
The report needs to be generated containing the difference of last and first row of each csv file as below:

The below code calculates the difference between the last and first row. How do we write the results into a separate file in the report format specified above?
def csv_subtract():
# this is the extension you want to detect
extension = '.csv'
for root, dirs_list, files_list in os.walk(csv_file_path):
for f in files_list:
if os.path.splitext(f)[-1] == extension:
file_name_path = os.path.join(root, f)
df = pd.read_csv(file_name_path)
diff_row = (df.iloc[len(df.index) - 1] - df.iloc[0]).to_frame()
CodePudding user response:
Using your code
def csv_subtract():
# this is the extension you want to detect
extension = '.csv'
for root, dirs_list, files_list in os.walk(csv_file_path):
df_dict = {}
for f in files_list:
if os.path.splitext(f)[-1] == extension:
file_name_path = os.path.join(root, f)
df = pd.read_csv(file_name_path)
# simplified indexing
# diff_row = (df.iloc[len(df.index) - 1] - df.iloc[0]).to_frame() # old
diff_row = (df.iloc[-1] - df.iloc[0]).to_frame() # new
df_dict[f] = diff_row
out = pd.concat(df_dict, names=["File Name"])
out.to_csv("path/to/report.csv")
Another Approach
Concatenate all the data upon read, groupby the file names, and calculate the differences within each group.
import numpy as np
import pandas as pd
if __name__ == "__main__":
# some fake data for setup
np.random.seed(1)
df1 = pd.DataFrame(
data=np.random.random(size=(5, 5)),
columns=list("abcde")
)
np.random.seed(2)
df2 = pd.DataFrame(
data=np.random.random(size=(5, 5)),
columns=list("abcde")
)
# I concatenate all dfs into one and use `keys` to identify which rows
# belong to which df
# in your function you could set keys to the file names
df = pd.concat([df1, df2], keys=["df1", "df2"], names=["file_name"])
# groupby the keys and calculate the difference between 0th and -1st rows
out = df.groupby("file_name").apply(lambda df: df.iloc[-1] - df.iloc[0])
print(out)
a b c d e
file_name
df1 0.383723 0.247937 0.31331 0.389990 0.729633
df2 0.069251 0.039360 -0.12154 -0.338791 -0.293208
Last step is to save this to a .CSV using pandas.DataFrame.to_csv
out.to_csv("path/to/file.csv")