I have a csv file called purchases.csv and I am trying to find how many purchases of each item in a month and every month seperately. I found every month seperately and how many purchases of each item. But if a item is never got purchased that month I need it to be shown as 0. This is my code so far;
#Reading the dataset
data = pd.read_csv('purchases.csv')
df = pd.DataFrame(data)
#Filtering the data
df['date']=pd.to_datetime(df['date'])
dataset=df[df['date'].dt.year == 2020]
#january
# Select DataFrame rows between two dates
januaryFilter = (dataset['date'] > '2020-01-01') & (dataset['date'] <= '2020-01-31')
january = dataset.loc[januaryFilter]
jan = pd.crosstab(january['item_id'], januaryFilter)
print(jan)
#february
# Select DataFrame rows between two dates
februaryFilter = (dataset['date'] > '2020-02-01') & (dataset['date'] <= '2020-02-28')
february = dataset.loc[februaryFilter]
feb = pd.crosstab(february['item_id'], februaryFilter)
print(feb)
This is my dataset.
session_id,item_id,date
3,15085,2020-12-18 21:26:47.986
13,18626,2020-03-13 19:36:15.507
18,24911,2020-08-26 19:20:32.049
19,12534,2020-11-02 17:16:45.92
24,13226,2020-02-26 18:27:44.114
28,26394,2020-05-18 12:52:09.764
31,8345,2021-04-20 19:46:42.594
36,14532,2020-06-21 10:33:22.535
42,11784,2021-03-01 15:17:04.264
44,4028,2020-11-27 20:46:08.951
48,24022,2020-04-15 17:29:15.414
49,2011,2020-05-01 12:34:29.86
52,12556,2020-03-21 11:49:07.324
75,28057,2020-05-24 17:27:54.288
77,4243,2020-09-20 21:37:20.838
107,4016,2020-01-15 06:07:23.177
108,18532,2020-06-06 17:25:15.508
113,21107,2021-05-05 14:15:07.278
115,25976,2021-05-27 10:24:05.043
119,434,2020-10-11 06:32:22.085
124,3732,2020-05-18 11:04:15.42
127,25117,2020-01-15 15:17:43.659
140,23502,2021-04-28 13:45:31.202
This is my output right now.
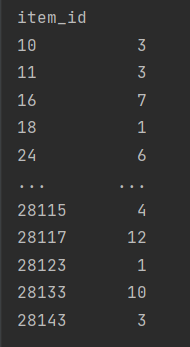
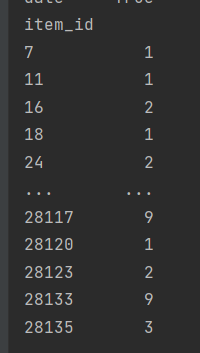
I know that there are item_id's (purchases) which are 0. But I can't see any. Can you help me with this problem ?
CodePudding user response:
You could do a join with the full set of items and fill missing values with zero (.fillna(0)).
Crosstab seems like overkill here; you are executing a simple groupby:
jan = january.groupby("item_id").session_id.count()
However, it seems to me that we could approach this more efficiently:
df["month"] = df.date.dt.month
results = (
df.pivot_table(
values="session_id",
aggfunc="count",
index="item_id",
columns="month",
).fillna(0)
)
results.head()
which should output one row per item ID, one column per month, and the number of purchases (count of session IDs) as the table values, with missing values filled as zero.
CodePudding user response:
I hope, it works for your solution. First I groupby data for month and item_id then I use pivot_table because I think you want to see data against item_id and if particular item_id is not in that month then it show 0.
import pandas as pd
#Reading the dataset
df = pd.read_csv('./stackoverflow_null_values_python.csv')
df['date'] = pd.to_datetime(df['date'])
df['year'] = df['date'].dt.year
df['month'] = df['date'].dt.month
df = df[df['year'] == 2020]
df_group = df.groupby(['month', 'item_id']).agg(n=('item_id', 'count'))
pd.pivot_table(df_group, values='n', index='item_id', columns='month', fill_value=0)