I have four different datasets. I have merged three of the dataframes correctly. I have same name column in 3rd and 4th dataset. When I merge it with 4th dataset. I am not getting the same name column values in well mannerd way. The user_id is repeating when I merge. I don't want to repeat the user_id. I want to see the value in the del_keys column where it's showing me NaN value rather than it's showing me the value in the last of table. Moreover, I want to merge values of same name column on the basis of their user_id.
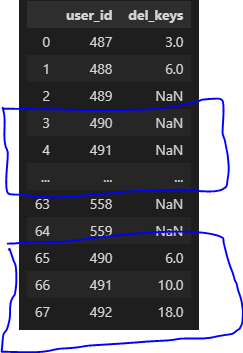
In the above image you can see what kind of problem I am getting.
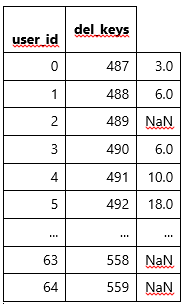
My expected output will look like. There should not be repeated user_id.
CodePudding user response:
using merge on user_id column
import pandas as pd
import numpy as np
df1 = pd.DataFrame({
'user_id': [1, 2, 3, 4],
'del': [1.0, np.nan, np.nan, np.nan]
})
df2 = pd.DataFrame({
'user_id': [3, 4, 5],
'del_keys': [1.0, 2.0, 3.0]
})
final=df.merge(df2,on="user_id",how="outer")
Combine first to get rid of Nan values and then drop duplicates
final["del_keys"]=final['del_keys_y'].combine_first(final['del_keys_x'])
final.drop(columns=["del_keys_x","del_keys_y"],inplace=True)
final.drop_duplicates(subset="user_id")
CodePudding user response:
I'm guessing that you use pd.concat to merge the dataframes.
Some dataframes:
import pandas as pd
import numpy as np
df1 = pd.DataFrame({
'user_id': [1, 2, 3],
'del_keys': [1.0, np.nan, np.nan]
})
df2 = pd.DataFrame({
'user_id': [3, 4, 5],
'del_keys': [1.0, 2.0, 3.0]
})
Merge using pd.concat:
df = pd.concat([df1, df2])
>>> user_id del_keys
0 1 1.0
1 2 NaN
2 3 NaN
0 3 1.0
1 4 2.0
2 5 3.0
Remove duplicates using pd.drop_duplicates:
(
df
.sort_values('del_keys')
.drop_duplicates('user_id', keep='first')
.sort_values('user_id')
)
>>> user_id del_keys
0 1 1.0
1 2 NaN
0 3 1.0
1 4 2.0
2 5 3.0
First, we sort the values by del_keys such that all NaNs are the bottom of the dataframe. Then we can drop the duplicates and keep the first occurrence for each user_id. Lastly, we can sort again to restore the original order.